Imaging A Hard Drive With non-ECC Memory - What Could Go Wrong?
2022-12-30 - By Robert Elder
I recently came home to visit with family, but right now as I write this, it's 1:00am and I'm running memtest86+ by myself in the basement.
The purpose of this article, is to provide a real-life case study to show why ECC memory is not a waste of money, and to provide a detailed account of how much time you can waste when bit flips become a part of you daily computing life. Having said that, the previous sentence is a bit of lie because this article is actually about more than that: Specifically, I will discuss various learnings that I had in the process of trying to image the hard drive of an old failing family computer, and the process of trying to restore the computer to fully working order. These learnings include:
- Is the process of diagnosing failing RAM very fast and easy? Nope!
- Should you use 'ddrescue' or 'dd' to image a failing hard drive? The answer depends on whether your memory is failing, and it may surprise you!
- So, you just imaged a drive with 'dd', but the hash checksum doesn't match? Pay attention to copy block sizes!
- Does the cheap new DDR3 RAM from eBay or NewEgg work in old motherboards? Nope, but sometimes yes.
- Does increased heat increase the likelihood of memory errors? I think it does.
Speaking of wasting time, I wasted huge amount of time on the analysis described in this article (4-6 hours per 500GB hard drive md5 checksum and ~12 hours+ per memtest run). This is probably the reason that you don't read too many articles like this one. It's not because bit flips are rare, but rather because most people who encounter them are smart enough to declare "It was probably just a ghost in my program!" and reboot the machine instead of investigating the issue and then wasting even more time writing a blog post to document the issue in excruciating detail.
The Overall Goal: A Simple Hard Drive Backup

My overall goal was to back up the data from an old family computer that was experiencing some 'problems'. This was actually a computer that I personally put together back in the year 2008. This would make it (2022 - 2008) = 14 years old! I found it fairly impressive that it was still running, despite the reports of occasional unexplained reboots.
Backing up an old computer... Sounds like a simple task, right? Well, allow me to make it more complicated for you:
Most people would probably just use the simplest backup approach of copying parts of the filesystem to an external flash drive to be adequate, but in my case I wanted to approach things from a thorough data recovery perspective. Therefore, I decided to image the entire hard disk to guarantee a perfect preservation of all data. This computer was old, so I figured it would be reasonable to assume that the hard drive might be already starting to fail.
I decided to use 'ddrescue' to image the drive since I know that 'ddrescue' maintains awareness of disk read errors. This is useful because it allows you to confirm if there are indeed problems reading from the drive, and the extent of how bad the drive health is. 'ddrescue' also attempts to carefully read the disk in a way that should preserve as much data as possible even when the drive is mechanically failing. You can even go back and try to re-try sectors that failed to read properly the first time.
And so, I changed the boot order of the machine, then booted into a live install of Ubuntu 20 with an attached USB disk to write the image to. I installed ddrescue, and ran it using the following command:
sudo ddrescue -vv -d -r0 /dev/sdb hd-image-ddrescued.img progress.log
Fortunately, ddrescue completed the imaging process without error and exited normally. Immediately after ddrescue finished, I decided to compute and md5 checksum of the raw disk device itself to compare it with the checksum of the image that I had just obtained:
md5sum /dev/sdb
The resulting checksum value was the following:
3d3085c04c3b148f6abb08ceb4b3d6e0 /dev/sdb
I also made sure to use the 'sync' command and properly unmount the external USB storage (where my copied image was located):
sync
By using the 'sync' command, I can ensure that any cached writes of the copied disk image are committed to my external hard drive before I try to unmount and remove it.
The ddrescue Image Checksum Doesn't Match!
On another, much faster computer, I did a checksum to verify the saved disk image, and to my surprise I got the following:
fc0e287bd2fc9f09c8f48a8ab675294f hd-image-ddrescued.img
That wasn't what I expected (I was expecting it to be 3d3085c04c3b148f6abb08ceb4b3d6e0). I started to wonder if I had done something wrong, or maybe I had some incorrect assumptions about running md5sum directly on the block device, or maybe I didn't understand what result ddrescue was supposed to produce?
I decided to reboot the computer and, again, boot into the Ubuntu live system. Throughout this process, I was careful to never mount or boot into the disk that I was imaging to avoid accidentially writing to it.
This time I decided to use the 'dd' command to clone the drive. If you don't specify a block size to 'dd', it will use a value of 512 bytes. If you try this for yourself, you'll probably discover that the copy progress of 'dd' is quite slow with small block size like 512 bytes. Now, if you do a bit of googling, you'll find that you can explicitly set the block size to a larger number to get a copy speed. Therefore, I chose a block size of '64K':
dd if=/dev/sdb of=image-dd-cloned.img bs=64K conv=noerror,sync
After I finished making the image with dd, I then ran another checksum on the block device to make sure that its md5sum had not changed:
md5sum /dev/sdb
3d3085c04c3b148f6abb08ceb4b3d6e0 /dev/sdb
This is the same value that I got the first time I calculated the checksum of this block device. This was re-assuring since it meant that the raw data on the disk had not changed even after rebooting the machine.
The dd Image Checksum Doesn't Match Either!
Next, I ran an md5sum of the disk image that I just created with dd:
md5sum image-dd-cloned.img
a974938dcfb9eb25121d33cdf673330f image-dd-cloned.img
What?!? That's now 3 different hashes, and none of them match! Am I losing my mind?
Then, I started to look a bit more closely at the file/device sizes:
fdisk shows the following:
Disk /dev/sdb: 465.78 GiB, 500107862016 bytes, 976773168 sectors
Disk model: Hitachi HDP72505
Units: sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
Disklabel type: dos
Disk identifier: 0x07650765
Device Boot Start End Sectors Size Id Type
/dev/sdb1 * 2048 206847 204800 100M 7 HPFS/NTFS/exFAT
/dev/sdb2 206848 976771071 976564224 465.7G 7 HPFS/NTFS/exFAT
and lsblk -b shows this:
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
sdb 8:0 0 500107862016 0 disk
├─sdb1 8:1 0 104857600 0 part
└─sdb2 8:2 0 500000882688 0 part
Why The Didn't The 'dd' Image Checksum Match? Block Sizes
So at least these two commands agree that the size of this drive is 500107862016 bytes. Now, how large are the disk images that I created?
ls -latr *
-rw-r--r-- 1 robert robert 500107862016 Jul 22 19:47 hd-image-ddrescued.img
-rw-r--r-- 1 robert robert 500107902976 Jul 23 20:09 image-dd-cloned.img
Ok, that explains why the hash of the image that was copied using 'dd' is different. The 'dd'ed image size is larger than the size of the block device! There is no way the checksums would match (ok sure, it could if there was a hash collision, but this is not an article on cryptographically secure hashes).
So why is the image size wrong when creating the disk image using 'dd', but not 'ddrescue'? Well, here's the first interesting take-away from this article:
It has everything to do with the block size that I supplied to the 'dd' command: The block size of the drive itself is 512 bytes, and its capacity is 500107862016, so 500107862016 / 512 = exactly 976773168 blocks. However, when running 'dd', I didn't use the default block size 512 because that's too slow. Instead, I specified a block size of '64K' or 1024 * 64 = 65536 bytes. If you calculate 500107862016 / 65536 you get 7631040.375. Last time I checked, you can't perform 0.375 of a hard disk read, so it's reasonable to assume that this gets rounded up to 1.0 hard disk reads, or '7631041 block reads of size 65536'. But guess what? 7631041 * 65536 = 500107902976 which is exactly the size of the image that I got with the 'dd' command! I checked the contents of this 'extra' data, and it simply contains zeros. The (somewhat presumptuous) conclusion that I will draw from this single experience is as follows: If the total size of the block device is not an integer multiple of the block size that you specify to 'dd', then you can expect to get zero-padding on the end of your image. In this case, your important data from the drive is not lost, but this result could lead to confusing results if you ever try to copy the image back (and find that it doesn't fit), or if you actually verify your hash checksums like I do. (Note: After publishing this video/article, I got an email providing more insight on this issue, and it likely has to do with the flags that I supplied to dd: See 2022-12-29 Note).
So, now let's pretend the end of the image past byte 500107862016 does not exist and re-compute the hash:
$ head -c 500107862016 image-dd-cloned.img | md5sum
3d3085c04c3b148f6abb08ceb4b3d6e0 -
Success! That's exactly the hash value that I got from directly hashing the block device!
Why The Didn't The 'ddrescue' Image Checksum Match?
Ok, we've made some progress getting the dd image checksum to match, now let's look into why the ddrescue one didn't produce the right hash value. It's probably another file size/block padding issue, right?
'ddrescue' seems to have produced an image that is exactly the right size, so extra padding at the end can't be the issue. Furthermore, the difference can't be due to an unexpected write/modification, because the image created with the dd command was taken later, and the md5 checksum was able to match then! Maybe I've misunderstood something fundamental about how ddrescue works and constructs images?
Let's see what the differences are with this 'cmp' command:
cmp -lb hd-image-ddrescued.img <(head -c 500107862016 image-dd-cloned.img)
I expected to see some huge section changed in the ddrescue image, but instead I got the following:
52185498315 107 G 307 M-G
73775329995 177 ^? 377 M-^?
86801068747 147 g 347 M-g
181705323211 107 G 307 M-G
186007311051 66 6 266 M-6
207345296075 55 - 255 M--
235067732683 76 > 276 M->
290357666507 37 ^_ 237 M-^_
300967236299 106 F 306 M-F
305192092363 147 g 347 M-g
313683256011 104 D 304 M-D
322162291403 167 w 367 M-w
355933934283 56 . 256 M-.
383209988811 124 T 324 M-T
It's worth explaining the above output a bit to make sure it's clear, so if we focus on this line:
52185498315 107 G 307 M-G
The above line means that at 1-based byte offset 52185498315 in the file 'hd-image-ddrescued.img', the 'cmp' command saw a byte that can be represented as octal 107 (hex value 0x47, text value G), but in the other file (or pipe in this case) 'head -c 500107862016 image-dd-cloned.img', it saw a byte with octal number 307 (hex value 0xC7 represented as M-G).
To be even more clear, here is a simple example of using the cmp command to compare the bytes 'a' and 'b':
cmp -lb <(echo -n 'a') <(echo -n 'b')
and the corresponding output from the above command:
1 141 a 142 b
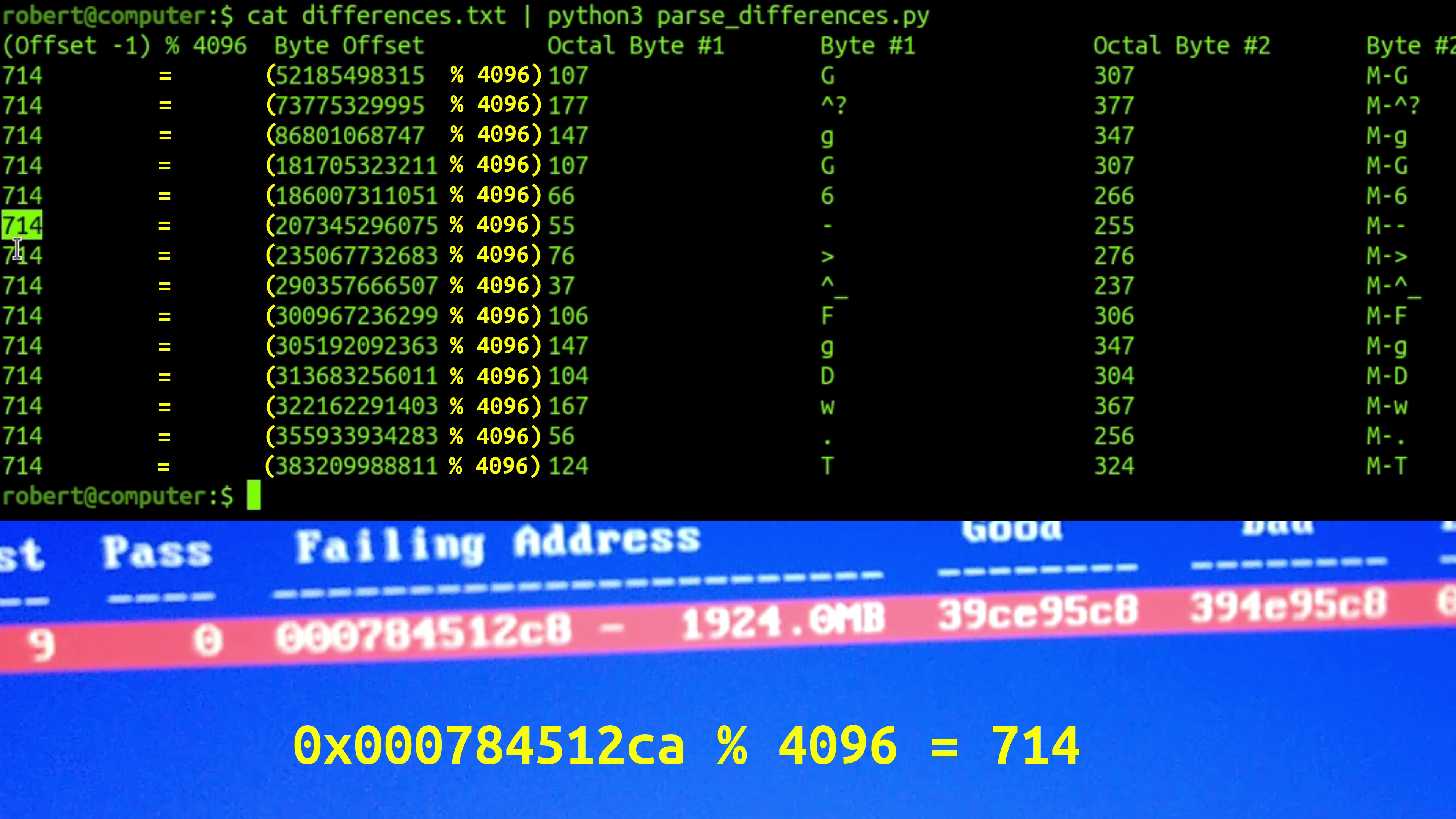
Now that you know how to read the output of the commands above, do you notice something in common with the differences in these bytes? Let's put the output from above in a file called 'differences.txt' and try to format the output a bit differently with this python script:
import re
import sys
for header in ['Byte Offset', 'Octal Byte #1', 'Byte #1', 'Octal Byte #2', 'Byte #2', 'Binary Byte #1', 'Binary Byte #2', 'Byte #1 XOR Byte #2']:
sys.stdout.write("{:<20}".format(header))
sys.stdout.write("\n")
for line in sys.stdin:
parts = re.split("\\s+", line.strip())
offset_number = int(parts[0])
octal_a = int(parts[1], 8) # Convert from octal
octal_b = int(parts[3], 8) # Convert from octal
parts.append('{0:08b}'.format(octal_a)) # Show binary representation of first byte
parts.append('{0:08b}'.format(octal_b)) # Show binary representation of second byte
parts.append('{0:08b}'.format(octal_a ^ octal_b)) # Compute binary XOR to highlight bits flips
for part in parts:
sys.stdout.write("{:<20}".format(part))
sys.stdout.write("\n")
After putting the above script into the file 'parse_differences.py', and running it like this:
cat differences.txt | python3 parse_differences.py
The output is as follows:
Byte Offset Octal Byte #1 Byte #1 Octal Byte #2 Byte #2 Binary Byte #1 Binary Byte #2 Byte #1 XOR Byte #2
52185498315 107 G 307 M-G 01000111 11000111 10000000
73775329995 177 ^? 377 M-^? 01111111 11111111 10000000
86801068747 147 g 347 M-g 01100111 11100111 10000000
181705323211 107 G 307 M-G 01000111 11000111 10000000
186007311051 66 6 266 M-6 00110110 10110110 10000000
207345296075 55 - 255 M-- 00101101 10101101 10000000
235067732683 76 > 276 M-> 00111110 10111110 10000000
290357666507 37 ^_ 237 M-^_ 00011111 10011111 10000000
300967236299 106 F 306 M-F 01000110 11000110 10000000
305192092363 147 g 347 M-g 01100111 11100111 10000000
313683256011 104 D 304 M-D 01000100 11000100 10000000
322162291403 167 w 367 M-w 01110111 11110111 10000000
355933934283 56 . 256 M-. 00101110 10101110 10000000
383209988811 124 T 324 M-T 01010100 11010100 10000000
Pay special attention to the column 'Byte #1 XOR Byte #2'. This columns shows the bitwise exclusive OR between each byte that had a difference in the 'ddrescue' image when compared against the image that was created with 'dd' (at least the first 500107862016 bytes of this image).
The exclusive OR shows us a '1' wherever the bits have 'flipped'. This makes it incredibly obvious that the only difference in the 'ddrescue' image is that these 14 individual bytes in the 500GB image file where the exact same high bit of our byte has flipped to 1 when it was supposed to 0. This is why the md5 checksum of the ddrescue image does not match the md5sum of the raw block device, or the one created using 'dd'!
Why Didn't The 'ddrescue' Checksum Match? Bit Flips In Memory
At this point, it's reasonable to suspect memory errors. Let's reboot into memtest86 and test out the memory:
Yup, that's a memory error!
But we're not done yet. We can go even deeper.
The failing address in the image is 0x000784512c8, or 2017792712 in decimal. The 'Err-Bits' was reported by memtest as 0x00800000'. This value of '0x00800000' represents a mask that shows exactly which bits of memory at address 0x000784512c8 contributed to the error. Since this machine uses little-endian, the address 0x000784512c8 points to the byte on the right-most end of the mask '0x00800000'. If we split up this machine word into bytes, we get Byte #3: 0x00 Byte #2: 0x80 Byte #1: 0x00 Byte #0: 0x00. and counting upward, one byte at a time, the exact byte where the single-bit error is located is in Byte #2: 0x80.
Therefore, the exact address of the individual byte where there error occurred was at memory address 0x000784512c8 + 2, which is 0x000784512ca, or 2017792714 in decimal.
Now, if we think back to our list of 'Byte Offsets' from the output of the 'cmp' command, we can look for even more patterns even though these might seem like random numbers at first:
Byte Offset
52185498315
73775329995
86801068747
181705323211
186007311051
207345296075
235067732683
290357666507
300967236299
305192092363
313683256011
322162291403
355933934283
383209988811
Remember, that the above numbers are byte offsets that tell us the number of bytes into the hard drive image that when the 'cmp' command found a difference. These are not addresses in RAM, so they won't have anything to do with the address of our failing bit in memory... Or do they?
The word on the street is that information is read into the computer's memory in chunks called 'pages'. There's also talk about how these so-called 'pages' are typically 4K or 4096 bytes in size. Let's modify our previous python script to show us the 'byte offset into the file modulo 4096' (with a -1 adjustment to account for 1-based indexing):
import re
import sys
for header in ['(Offset -1) % 4096', 'Byte Offset', 'Octal Byte #1', 'Byte #1', 'Octal Byte #2', 'Byte #2', 'Binary Byte #1', 'Binary Byte #2', 'Byte #1 XOR Byte #2']:
sys.stdout.write("{:<20}".format(header))
sys.stdout.write("\n")
for line in sys.stdin:
parts = re.split("\\s+", line.strip())
offset_number = int(parts[0])
octal_a = int(parts[1], 8) # Convert from octal
octal_b = int(parts[3], 8) # Convert from octal
parts.insert(0, str((offset_number-1) % (4 * 1024)))
parts.append('{0:08b}'.format(octal_a)) # Show binary representation of first byte
parts.append('{0:08b}'.format(octal_b)) # Show binary representation of second byte
parts.append('{0:08b}'.format(octal_a ^ octal_b)) # Compute binary XOR to highlight bits flips
for part in parts:
sys.stdout.write("{:<20}".format(part))
sys.stdout.write("\n")
And the output is now this (pay attention to the first column):
(Offset -1) % 4096 Byte Offset Octal Byte #1 Byte #1 Octal Byte #2 Byte #2 Binary Byte #1 Binary Byte #2 Byte #1 XOR Byte #2
714 52185498315 107 G 307 M-G 01000111 11000111 10000000
714 73775329995 177 ^? 377 M-^? 01111111 11111111 10000000
714 86801068747 147 g 347 M-g 01100111 11100111 10000000
714 181705323211 107 G 307 M-G 01000111 11000111 10000000
714 186007311051 66 6 266 M-6 00110110 10110110 10000000
714 207345296075 55 - 255 M-- 00101101 10101101 10000000
714 235067732683 76 > 276 M-> 00111110 10111110 10000000
714 290357666507 37 ^_ 237 M-^_ 00011111 10011111 10000000
714 300967236299 106 F 306 M-F 01000110 11000110 10000000
714 305192092363 147 g 347 M-g 01100111 11100111 10000000
714 313683256011 104 D 304 M-D 01000100 11000100 10000000
714 322162291403 167 w 367 M-w 01110111 11110111 10000000
714 355933934283 56 . 256 M-. 00101110 10101110 10000000
714 383209988811 124 T 324 M-T 01010100 11010100 10000000
And just like that, these 'seemingly random' image file byte offsets contain an incredibly obvious pattern: They are all congruent to 714 modulo 4096. And, remember that exact address of the failing memory byte, 0x000784512ca? Go ahead and calculate what it's congruent to modulo 4096. I dare you. It's 0x000784512ca % 4096 = 714 in decimal.
If that's not enough to convince you, try piping the output above through the following awk command:
cat differences.txt | python3 parse_differences.py | awk -F '' '{for(i=1; i<=NF; i++){if((i>(60-(NR-14)*1))&&(i<(86+(NR-14)*1))&&NR<15&&(((i-73)^2/3^2)+((NR-9)^2/1^2)>3)) printf "1"; else printf " "} printf "\n"}'
Take one look at the output and the truth becomes obvious:
1
111
11111
1111111
111111111
11111111111
11 11
11 11
1111 1111
1111111111111111111
111111111111111111111
11111111111111111111111
1111111111111111111111111
Doesn't this remind you of something?
What Can We Conclude So Far?
At this point, we've confirmed that there are in fact 'bit flips' occurring in memory, and furthermore, we can make a precise association between the individual bit flips that were reported by memtest in hardware, and the bit flips that we saw in the 'ddrescue' software as we imaged the hard drive image. This association comes from the fact that all the failing address were both congruent to 714 modulo 4096. The value '714' (modulo 4096) in relation to the hardware itself is not significant, but the fact that we also saw the exact same value, 714 (modulo 4096), through the software activity of 'ddrescue' seems like more than a coincidence. It is reasonable to conclude that the 'ddrescue' program requested heap memory pages from the operating system that were 4096 bytes in size as a temporary storage for data that was coped during the imaging process of the hard drive. By chance, some of these memory pages just happened to include the bad physical memory address noted above (0x000784512ca), causing the bits to be flipped and corrupting the resulting image.
So, if we got 14 bit flips when creating the image with 'ddrescue', how come we got 0 bit flips when copying with the 'dd' command? That's a good question, and I don't have a great answer, but I would speculate that it has something to do with how 'ddrescue' uses heap memory internally compared with how 'dd' so. The 'dd' command is much a much simpler tool to do block copies of information without trying to maintain data structures to re-construct and retry failed sectors in the same way that 'ddrescue' does. It's likely down the fact that the 'dd' command simply makes less use of heap memory or access it in a different pattern compared to the way the 'ddrescue' command does.
Whatever the reason is for the difference in behaviour between 'dd' and 'ddrescue', we could argue that you might prefer to use one or the other tool to image a drive depending on the circumstances. In cases where you suspect a hard drive to be failing, you would prefer to image the drive using 'ddrescue'. However, in cases where you suspect that the memory is failing, then you would prefer to image using the 'dd' command. If you suspect that either could be failing, you would image the drive using both methods and then verify by computing the hash of all three: The raw block device, the dd-based image and the ddrescue-based image.
So, There Are Memory Errors - What Now?
Okay, so at this point, I was sure that there are definitely memory errors in this computer. However, I already have my fully intact and verifiably correct hard drive image despite the failing memory, so we're done right? Nope! It's time to replace the memory and then verify that the hardware issue has been fixed!
One of the first changes that I made to the hardware was to replace the power supply with a brand new one. Power supplies contain components like capacitors that can degrade over time.


I didn't actually do any kind of fancy analysis to evaluate whether the power supply really did have any problems (I don't even have the kind of equipment you'd need to do such a test), but I felt it was safe to assume that after almost 15 years of operation, a replacement couldn't hurt.
Replacing the power supply might seem like a strange place to start debugging a problem with the computer's memory, but if there really was a problem with the power supply then you can end up with all sorts of extremely strange and hard to debug problems with the rest of your hardware/software. When the power supply functions correctly, it should convert 120V or 240V AC into well filtered 3.3V, 5V or 12V DC. However, if the power supply starts to fail, these DC voltages could be too high or low, or experience ripple.
Many experienced computer users have heard of the idea that bit flips are extremely rare occurrences that are almost always caused by cosmic rays from space. In my experience, bit flips are a much more frequent occurrence that can typically be attributed to a presistent hardware issue (like a failing power supply).
With the power supply replaced, my weeks-long saga of troubleshooting the memory began:
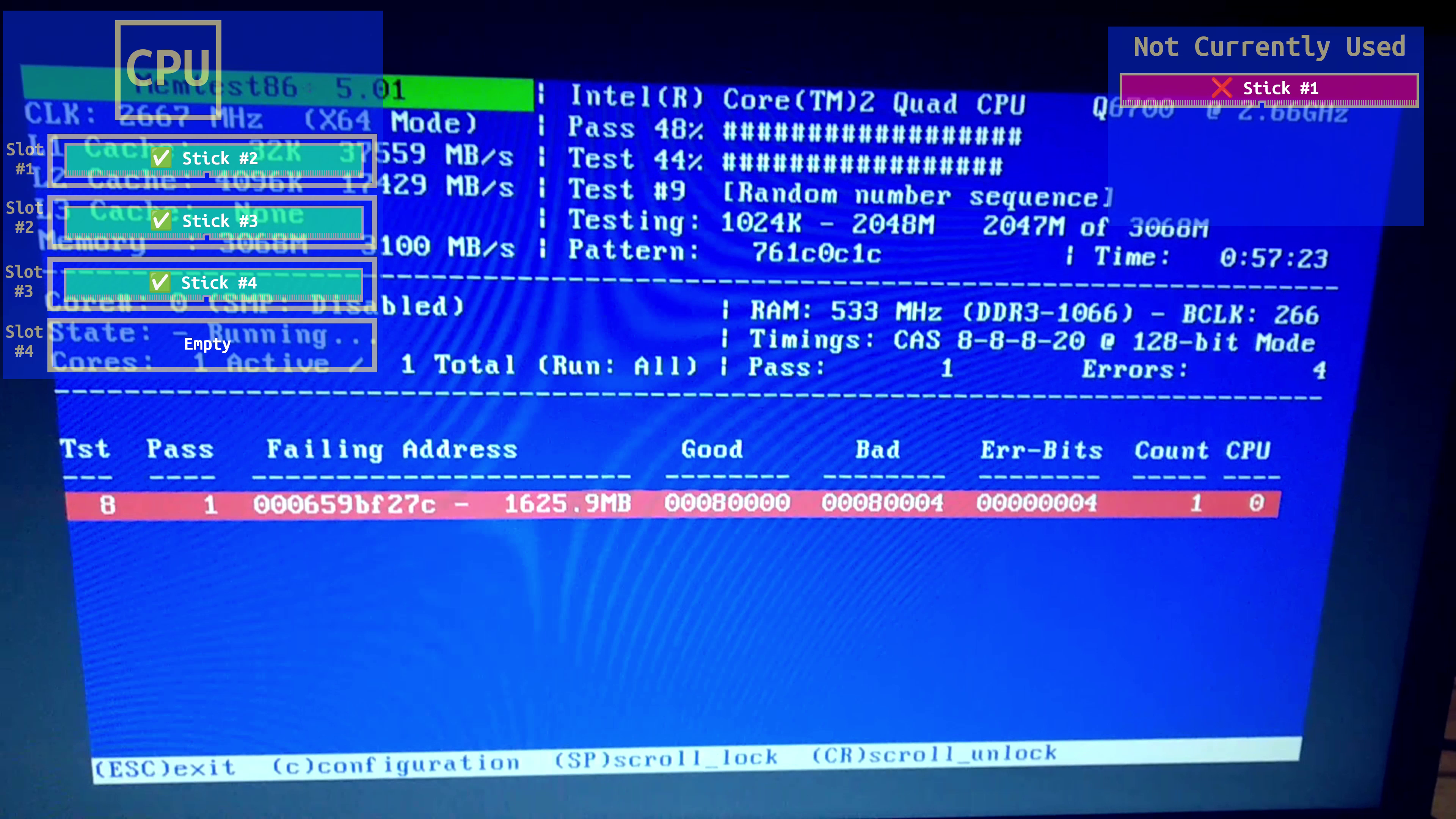
First, I started with a test to confirm that I still had memory failure even after replacing the power supply. Indeed, memtest was still identifying failures after just a few minutes. For this test, I still had all 4 memory slots populated with a 1GB stick each. I should also mention that this computer had multiple failed case fans, so it was running hotter than normal.
I decided to try and use a process of elimination to identify whether there was a single stick, or possibly multiple sticks that were the root cause of the problem. I ran another test with only a single stick of ram in the slot closest to the CPU. After 40 min, it had 0 errors, so I concluded that this stick might be Okay.
One Bad Stick Of RAM Identified
Then, to be extra thorough, I put all 4 sticks back in and ran memtest again. A common cause of memory errors is RAM that isn't making a good connection with the slots on the motherboard. Sometimes, simply taking the RAM out and putting it back in will fix the issue. This wasn't the case here, because more errors appears within a few minutes.
Based on the addresses where the memory errors occurred, I started to suspect that there might actually two sticks of RAM that were bad. I ran another test where I kept only two of these sticks in the motherboard. This time, the test ran for 1 hours 22 minutes without reporting any errors.
At this point, I was starting to suspect that maybe it wasn't even the RAM that was bad, but perhaps the RAM slots (or the motherboard, or the CPU) that was bad. I ran another test where I put the two remaining sticks of RAM into the exact same slots that I had just seen working without errors in the previous test.
This time I got errors again. So now, I had the errors down to two stick of ram in the two slots that were closest to the CPU. I first tested again with only the first stick of RAM in the slot closest to the CPU. This time, it ran for 1 hours and 46 minutes with no errors. From this, I concluded that the culprit probably wasn't this stick or the slot closest to the CPU.
Next, I tested the second of the two RAM sticks in second slot away from the CPU. I did get an error just before the 1 hour mark. So, now I had localized the error down to one stick of ram in at least one of the slots.
In order to try and rule out a problem with the RAM slot itself, I did another test with this exact same stick in the slot closest to the CPU, and got another failure at almost the three hour mark.
I found it a bit odd that it took a lot longer to trigger errors in this slot, so I did another identical test of this RAM stick in this same slot while the computer was still warm. Again, it took about 3 hours for errors to pop up.
In order to completely rule out any involvement of the second RAM slot itself, I decided to do even more testing in this slot with one of the other sticks of RAM that I hadn't yet observed failures on. This test ran for over 10 hours, and did not result in any error. At this point, I concluded that I had identified at least one bad stick of RAM, since it failed with the same error mask in multiple slots. I put a mark on this stick to identify it as stick #1. Furthermore, I concluded that the motherboard itself (or the CPU) was not likely to be the root cause of the failures. I also concluded that the stick that ran for over 10 hours without error was probably okay. I then marked this stick to identify it as stick #2.
Next, I took one of the remaining untested sticks and did the same test on it in the second slot away from the CPU. This stick ran for over 11 hours without any errors. I identified this stick as #3.
Finally, I tested the last stick, #4, for 12:47, and did not seen any errors. So far, I've identified #1 as bad, and #2, #3, and #4 as likely good.
The Other 3 Sticks Are Confirmed 'Ok', Right? - Not So Fast...
So, the next thing to do is put these three so-called 'good' sticks together, and test them out because hopefully they should work, right? Nope! One failure after only a hour:
I wasn't completely sure about how the RAM addresses mapped to the actual RAM slots, and I had a hunch there might be an issue with the stick in third slot away from the CPU. I decided to take out all but this stick in the third slot, and do another test. I also hadn't tested much in this slot before, so I figured it was worth a shot. I was hoping to get lucky and catch a failure in this stick, but after an hour there were still no errors on this stick.
At this point, it was clear that testing individual sticks one at a time wouldn't quickly reveal more failures, so I decided to move to an approach of testing more than one stick at once. I would also start being more careful in tracking the stick and slot numbers, and logging the exact failure addresses.
So, for the first test, I put sticks in the order #3, #2, #4 and got my first failure just before the 2 hour mark. The was only one error and its mask was 0x100. The failing address was 0x000b08f3204.
For the second test, the sticks had the order #2, #3, #4, and it had failures by the 32 min mark. There were 7 failures with mask 0x200 at address 0x000b4218f9c, and 1 failure with mask 0x4 at address 0x000b2cdf93c.
For the third test, the sticks had the order #2, #4, #3, and I noted the first failure occurred at the 1hr 49min. This test had logged 2 errors with mask 0x4 at address 0x000659bf27c.
For the fourth test, the sticks had the order #4, #2, #3, and I noted the first failure at the 36 min mark. This test had logged 1 error with mask 0x100 at address 0x000b08f3204. As I started to review the data from all four tests, I realized that this was probably the worst possible result:

Trying To Make Sense Of More Failures
From the above test results, you can see that test #1 and test #4 both have a failure at the exact same address with the exact same bit mask. If you look at the RAM slot orderings for these two tests, you can see that the only commonality between them is position of the #2 stick. If you assume that stick #2 is the only bad stick among these three (or slot) then you would expect to also see a clear pattern between the failures in test #2 and test #3. The #2 stick is in the same location between test #2 and test #3, but clearly the failures between these two tests show locations that are in different megabytes.
From this, I concluded the following: The remaining hardware error in these last 3 sticks of RAM cannot be due to a single bad stick of RAM. It must either be due to multiple bad sticks of RAM, or some sort of less obvious common-mode problem. There may be an issue motherboard's ability to refresh the RAM states when more than a couple RAM sticks are present. Perhaps there is a leaking capacitor somewhere on the motherboard, or maybe the presence of multiple sticks of RAM causes an intolerably long increase in the time between refreshes.
I also haven't given much consideration toward the selection of RAM timings, voltages, and frequencies. So far, I've just relied to BIOS to automatically select the right default values, and it is beyond my capabilities to select better values.
At this point, I felt that I had done just about everything I could do to isolate which sticks of RAM were bad, and that it was probably worth giving up on all 4 of the original sticks of RAM.
Replacing Thermal Paste & Installing New Fans
For this next bit of hardware improvement, I decided to replace all the thermal paste and install a new CPU fan and replace all the case fans:

Now, with all the fans replaced, I decided to start up memtest again with these three sticks and see if the cooler temperature had much influence on the rate at which errors appear.
I let this test run for almost 18 hours, and it only recorded 1 error during that time. This is contrasted with the exact same test that I did before where I would usually get multiple errors within the first couple hours. From this, I conclude that letting your computer get very hot is a one very likely cause of increased memory errors.
Buying Replacement Memory (Attempt #1)
Back when I had seen the first memtest error, I decided to order some new ram from china and since that finally arrived, I decoded to test it out too. It cost me $30 including shipping to get these 4 brand new sticks direct from China:

I started out by putting all 4 sticks of RAM in, and tried to boot it up. Unfortunately, the motherboard didn't like this RAM and I only got POST beeping codes for memory issues. Then, I removed 3 of the sticks so that only one remained, and tried again. It still just gave me beeping codes for memory issues. Around this time, I started doing more research and discovered that there is another important variable to consider when buying RAM, and that is the 'RAM density'. Apparently, older motherboards cannot handle newer high density RAM. This is a problem because most of the cheap RAM that you find online does not give any indication of what it's density is, so there's no way to know if it will work until you buy it and put it in the motherboard.
Buying Replacement Memory (Attempt #2)
I decided to give it another shot, so I bought some more cheap RAM off of eBay:

This here is supposed to be 2 sticks of 2GB each. From the label on the RAM it looks like it might actually be 4GB sticks, but the description assured me that they were indeed 2GB sticks, which are supposed to work in this motherboard. For the record, the motherboard is an Intel DP45SG.
I installed this RAM and found that it also wouldn't work. I tried a few times with only one stick and I also tried re-arranging the RAM slots a couple times, but this only produced more POST error codes.
Buying Replacement Memory (Attempt #3)
Naturally, the next step was to buy even more RAM off of eBay:

I believe these ones were actually used sticks. They are 1GB each, and they appear to be a mixed lot. For this set it looks like there is a high probability that the RAM timings, voltage and density may all be different and possibly incompatible. I decided to start by not paying any attention to this detail, and just put them in all at once and see what happens.
Clearly, it doesn't work with all 3 sticks of RAM together, so I tested out each stick individually, and to my surprise, all three of these sticks work!
After looking a bit more carefully at the voltages and timings of these sticks of RAM, there are two of them that appear to be fairly similar, so I decided to try installing both of them together.
And fortunately, it did manage to boot up successfully and I was able to get into memetest:
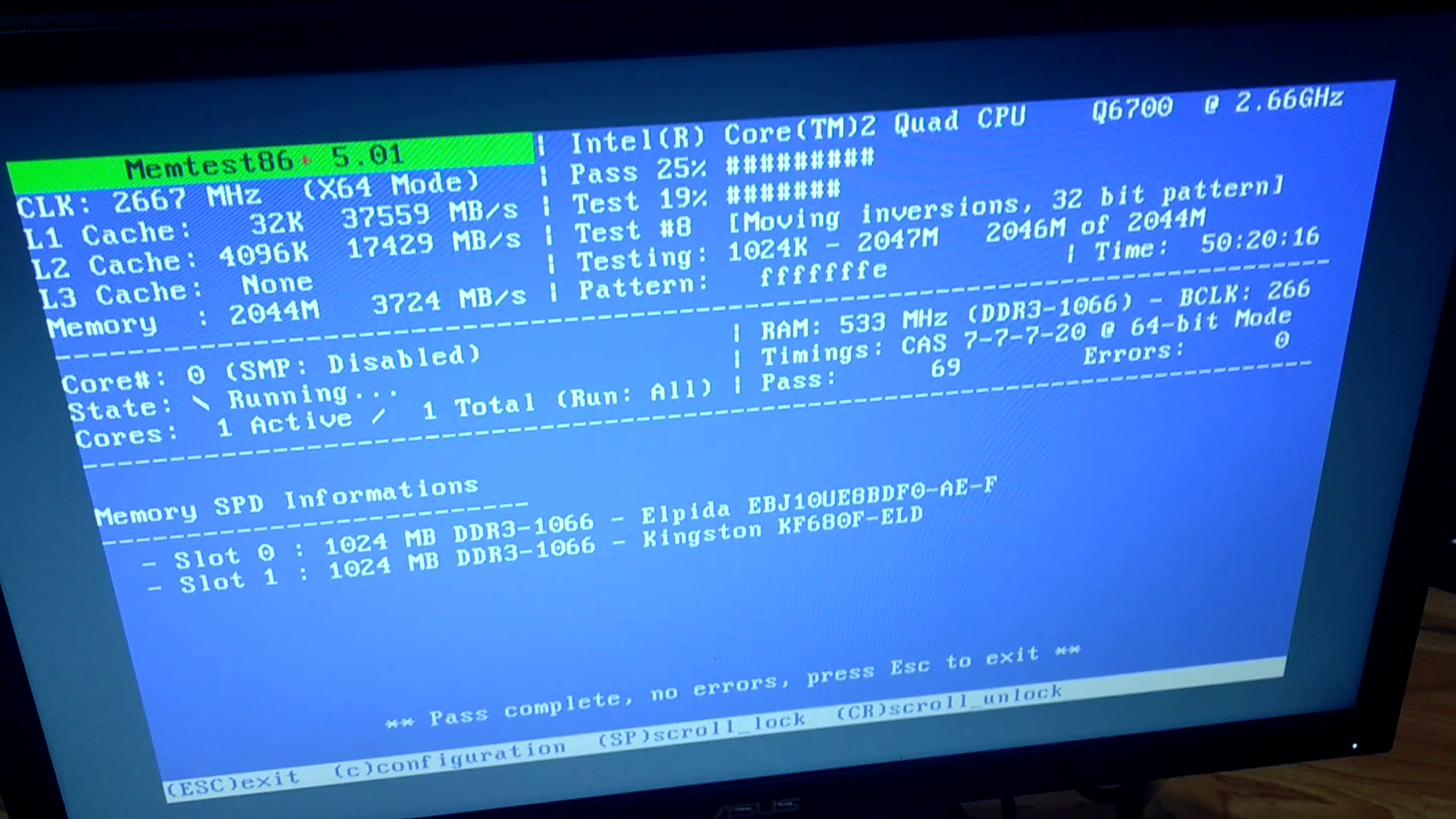
I decided to let memtest run with these sticks for 50 hours, and after 69 passes with 0 failures, I think it's time to declare this a success. This 2GB of memory is a lot less than the 8GB that I wanted to install in this machine, but given how hard it is to find old RAM that actually works, I'll have to declare this as 'good enough'.
Conclusion
So what kind of conclusions can we draw from the experience described above? There are a lot of mini-lessons and learnings, but the most significant idea that I want to impart to the reader is the scale of how much time I wasted on debugging this. With cheap consumer non-ECC memory, your bits can flip here and there, and you'll have no idea! The first indication that I had that there was even a problem was a silently corrupted hard drive image. To even detect this, I needed the patience and discipline to verify the checksum on a 500GB file! Imagine how much more time I could have wasted if I didn't bother to verify the checksum and made use of an important business document that contained one of the 14 bit flips?
Now some of you might think that it's a bit melodramatic to even consider it a big deal when only 14 bits per 500GB of data are corrupted, but that's really what defines the difference a user that needs ECC memory and a casual user who doesn't. Some people need computers to produce exactly correct results all the time, and some people are okay with just rebooting the machine when it mis-behaves and then blaming the problem on 'ghosts'.
Having said this, the performance and cost advantage of using consumer-grade non-ECC memory compared to ECC memory is getting smaller and smaller every year. Hopefully, one of these days, memory and CPU manufacturers will finally bite the bullet and declare "We are permanently discontinuing non-ECC memory and CPU production forever. Moving forward, all consumer grade memory and CPUs will use error correction.". Once this happens, we can finally stop having conversations about this topic, and people like me will no longer need to write articles like this one.
Okay, now time to go upstairs and see what everyone else in the family is up to. Oops, everybody went to bed already.
2022-12-29 Update About 'dd' Image Padding Issue
After publishing the video above, I got an email from someone who suggested an explanation for the padding issue that I encountered above. The email reads as follows:
Hi, I just saw your video on the non-ECC RAM corrupted hard drive image. I don't like commenting on social media, so I thought I'd send you an e-mail instead.
The reason your dd command creates an image size that does not match the size of your block device is because you're running "dd conv=sync". The sync conversion option explicitly tells dd to pad every input block with NULs up to the input block size, which is the behaviour you're seeing. I assume you're trying to tell dd to use synchronous I/O, but that's a flag, not a conversion option.
While this is documented in the dd man page, it is really confusing.
If you really want synchronous I/O, try:
dd if=/dev/whatever of=image bs=64k conv=noerror iflag=sync oflag=sync
Although I've never used synchronous I/O in dd, I just run "sync" afterwards as you do since I like buffering and caching during the transfer :)
No affiliation with dd, gnu, youtube or anything else. I just saw your video and wanted to clear it up, since I recognized the problem.
Have a good one, Andreas
--End Of Email--
I must admit that I have never taken the time to gain a detailed understanding of all the flags that 'dd' supports, and I have not personally taken the time to verify the suggestions in the email described above. However, I will keep this note here as it may help others (and I will likely try this out myself some time in the future).
 A Surprisingly Common Mistake Involving Wildcards & The Find Command
Published 2020-01-21 |
 Buy Now -> |
 A Guide to Recording 660FPS Video On A $6 Raspberry Pi Camera
Published 2019-08-01 |
 The Most Confusing Grep Mistakes I've Ever Made
Published 2020-11-02 |
 Use The 'tail' Command To Monitor Everything
Published 2021-04-08 |
 An Overview of How to Do Everything with Raspberry Pi Cameras
Published 2019-05-28 |
 An Introduction To Data Science On The Linux Command Line
Published 2019-10-16 |
 Using A Piece Of Paper As A Display Terminal - ed Vs. vim
Published 2020-10-05 |
| Join My Mailing List Privacy Policy |
Why Bother Subscribing?
|