Modelling C Structs And Typedefs At Parse Time
2017-03-30 - By Robert Elder
Introduction
Updated December 2, 2017: Made a few corrections.
This article was written to complement An Artisan Guide to Building Broken C Parsers.
The purpose of this article is to attempt to describe an algorithm for modelling typedefs, struct, union, enum tag specifiers, and their associated scope levels at parse time. The hope is to make this algorithm accurate enough for use in my C compiler. This article will make heavy use of C standard jargon and the intended reader will be one who is either interested in learning how to compile (specifically how to parse) the C programming language, or someone who is simply interested in learning how C works in meticulous detail. The C language version depicted in this article will be ISO C11 unless otherwise specified.
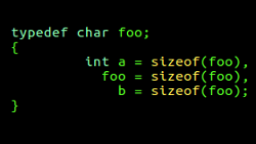
An Example
Code View |
Scope Tree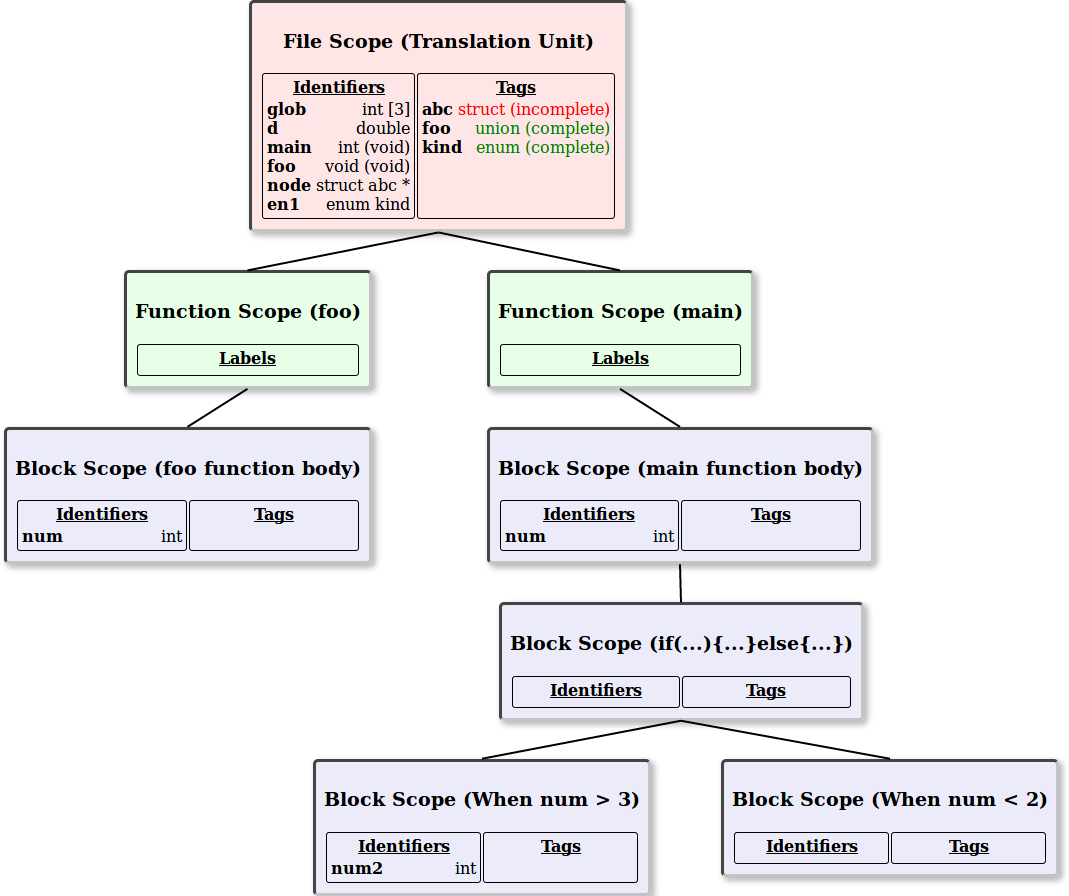
|
The above comparison of code and the corresponding scope tree serves as an introduction to understanding how tags and identifiers can be modelled in the C programming language. Several observations can be noted from the above diagram:
- So-called 'Ordinary Identifiers' consist of variables and typedef names. Variables and typedef identifiers occupy the same namespace, so once an identifier has been declared as either a typedef or an identifier, it cannot be re-declared as the other in the same scope.
- So-called 'Tags' which are the identifiers that denote various struct, union, or enum declarations. All identifiers for struct, union and enum tags occupy the same namespace.
- Scoping is hierarchical and can be considered a tree structure. All typedefs, variable declarations, struct, union, and enum declarations occupy a namespace at their respective place in the scope tree structure where they have been declared.
- Enumeration constants go into the identifier namespace, while the enum tag name goes into the tag namespace.
- Tags (struct, union, enum) and typedefs which most programmers only ever see at file scope, can be declared at any scope.
- 'Function Scope' is somewhat special in that only label identifiers (for gotos) can occupy this scope.
- The definitions of struct or union types are not depicted in the images in this article. It is assumed that they are stored elsewhere in another data structure. The combination of scope level and tag name together is required to identify one unique tag definition, since you can have multiple definitions of 'struct foo' throughout your program in different scopes.
The C11 standard defines 4 different types of scope levels[1]:
- Function Prototype Scope - Which is only used in non-function definition descriptions of functions (prototypes, function pointer declarations etc.).
- Block Scope - Which takes care of the scoping related to any compound statements either in an entire function definition or a control structure.
- Function Scope - This one is somewhat special because it only stores goto labels that occur inside the function. Variables and parameters in a function go into 'Block Scope'.
- File Scope - This is where functions and globals are declared.
An example of all four of these scope types is provided in the following example:
Code View |
Scope Tree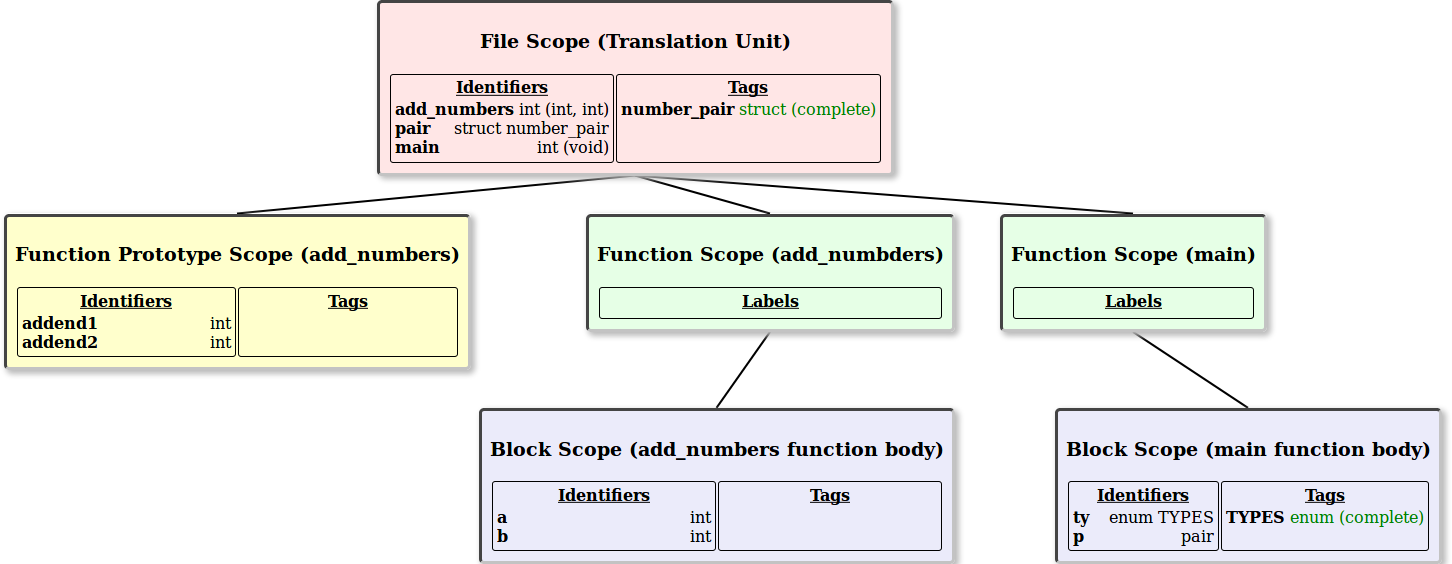
|
Looking Up Identifiers
The following illustration depicts a method for looking up the types of identifiers that is almost always correct. We'll review the simple and almost correct version first, and then explore the subtle (and rather serious) case where it is not correct:
Code View |
Scope Tree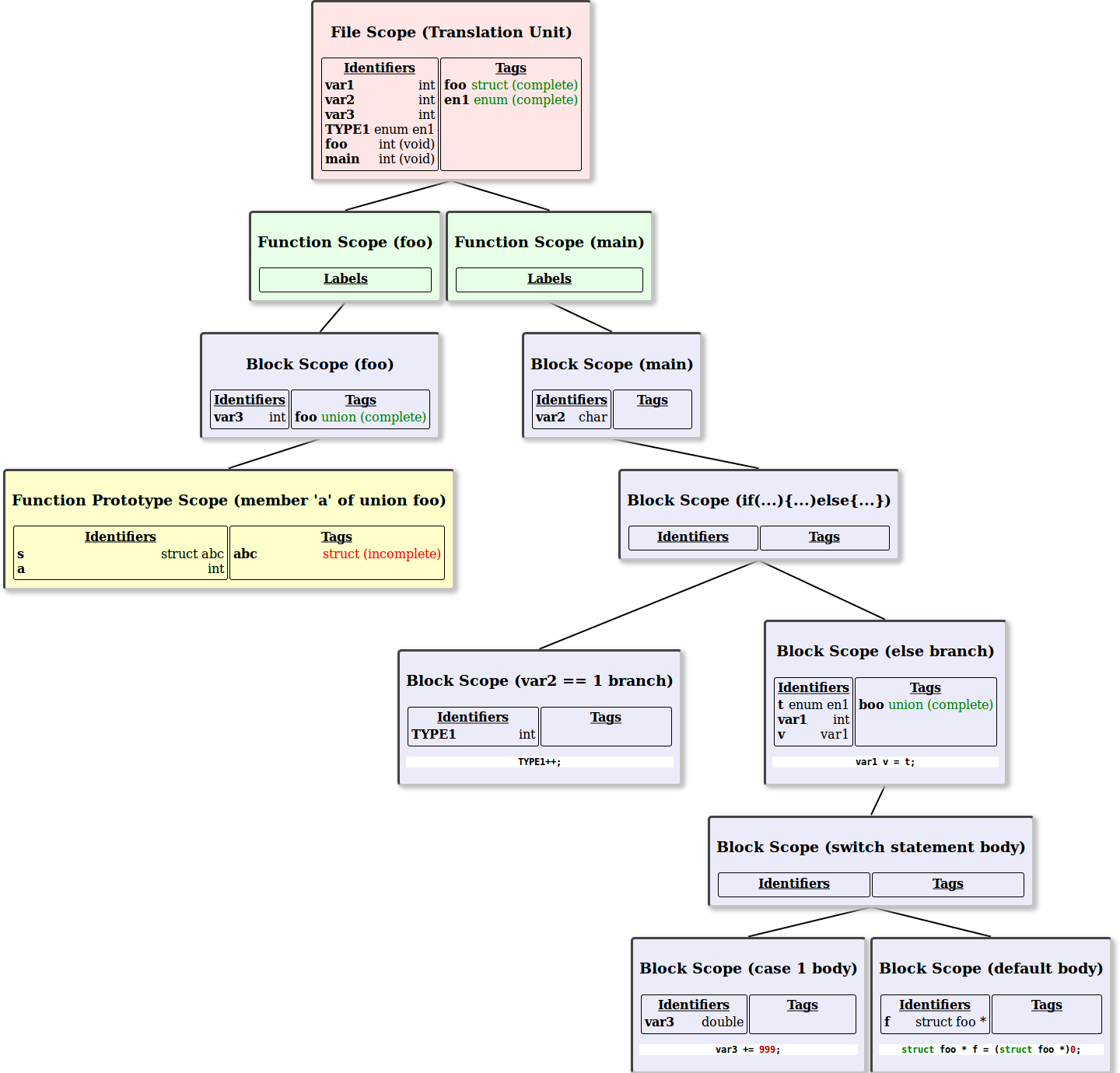
|
The general algorithm is this: When looking up the type of an identifier in the tag or identifier namespace, begin in the current scope checking either the tag or identifier namespace as necessary for an entry with a matching identifier. If a match is not found in the current scope, travel up to the next scope working toward the root file scope. This works for variables, typedefed types, struct, enum, and unions. Note that all tags in a given scope share the same namespace, so if you find a tag with a matching identifier, but a different tag type (say a struct re-declared as a union), then that will be considered a 'match' that results in an compiler error since the tag type cannot be changed in a later re-declaration. For the case of variables or typedefed types, if no match is found you'll end up with an undeclared identifier error. For struct and union tags, if no match is found all the way up to the root node, this can be considered a 'declaration' of an incomplete tag in the originating scope. Enums are not permitted by the standard to allow forward declarations, so incomplete enum declarations that are not also definitions should result in an error. Finally, variables and typedefed types in the same scope share the same namespace, so the final parse tree will depend on whether the first thing found is a typedef or a variable declaration.
Let's review a few examples from the image above starting with the look up required to determine the origin scope of 'struct foo':
- Begin at the 'default body' block statement with the initial reference to 'struct foo'.
- Because this is a tag (a struct), we only check the tag namespaces for matching identifiers.
- No tags declared in this scope, move up to parent scope.
- No tags declared in switch statement body, move up to parent scope.
- Only one tag 'boo' declared in else statement body. No match, move up to parent scope.
- No tags declared in if ... else ... body, move up to parent scope.
- No tags declared in main, move up to parent scope.
- Matching tag 'foo' found at file scope. Search complete.
Now let's review the lookup of 'TYPE1' in the expression 'TYPE1++' inside the var2 == 1 branch:
- Begin at the 'var2 == 1 branch' block statement with the initial reference to 'TYPE1'.
- A match is found in this scope, and TYPE1 is found to have type 'int'.
Finally, let's look at the case of looking up 'struct abc' in the function prototype scope of the member 'a' inside the union declaration of function foo:
- Begin at the function prototype scope.
- In the image depicted above, there is an entry for 'abc' in the tag namespace of the function prototype. However, the image above shows all declarations and scopes after the entire program has been parsed. At the moment of parsing 'struct abc', no such entry for 'abc' exists yet in this tag scope.
- Since there is no entry for 'abc' in the tag namespace in this scope level, move up to the parent scope.
- This scope only has one tag called 'foo' which does not match. Move up to parent scope.
- At file scope there is also no matching tag for 'abc', so the search finishes without finding a result.
- Since there is no match, we now assume that this is a declaration of an in-complete struct type in the originating scope.
- The originating scope is the function prototype, and if you compile this code you'll note that you get a warning about this line because declaring the tag type inside a function prototype without a forward declaration in a higher scope means that you'll never be able to actually declare an instance of that tag type.
When Does It Not Work?
The case where the above algorithm does not work is rather subtle. If you perform the lookup algorithm as mentioned above as you parse the program line-by-line from top to bottom, then you will be able to correctly associate variable or tag references with their appropriate declaration by propagating toward the root scope.
However, using the approach described above, if you re-perform the same lookup algorithm for a given identifier after your scope tree model has been fully constructed, you will get the wrong answer in the following case:
int var = 1;
int main(void){
int a = var; /* Compiler needs prevent referencing later 'var' in current scope. */
int b = a;
int var = b;
return 0;
}
And here is another case that demonstrates the same problem with structs:
struct foo{
int j;
};
int main(void){
struct boo{
struct foo f; /* Compiler needs prevent referencing later 'foo' in current scope. */
struct foo {int i;}g;
};
return 0;
}
The issue in both of the above cases is that we reference an identifier or tag (var in the first case, foo in the second case) inside of main that refers to a declaration outside of main, but then we re-declare that same identifier/tag later in the same scope. If you were to apply the same algorithm of 'check every scope level for a match' starting in the scope where the reference occurs, then you would end up matching with the declaration that occurs after the reference in that same scope. Finally, the problem isn't limited to situations where the same variable identifier is used multiple times in the same scope, it can also occur if the same identifier is used later in any intermediate scope:
int var = 1;
int main(void){
if(1){
int a = var; /* Compiler needs prevent referencing later 'var' in main body scope. */
}
int a = 2;
int b = a;
int var = b;
return 0;
}
Therefore, you can draw the following conclusion: Whatever model the parser ends up building must include at least one of the following things.
- Variable and typename references will need to remember some sort of ordering so that we can avoid the case where an identifier in the current scope could incorrectly reference a declaration that occurs later in the current scope, instead of correctly referencing the declaration from the outer scope.
- We can remember the type or origin scope of the type for each identifier as it gets parsed so that this information can be passed to later compilation stages.
Performing lookups of the scopes (and types) of identifiers will be necessary anyway, because of the ambiguity between identifiers which are used as variables and identifiers which are used for typedefed types. This difference between typedefed identifiers and ordinary variables is important because it will affect the shape of the parse tree, and it will require the parser to introspect on the various scope levels and identifiers which have been declared in them.
Here is pseudo-code for the general lookup algorithm:
/* The algorithm for looking up a variable or tag in the scope tree
(Only valid at parse time)
. */
get_closesest_declaration(current_scope, identifier, tag_or_identifier){
the_namespace = (tag_or_identifier == tag) ? current_scope.tag_namespace : current_scope.identifier_namespace;
if(current_scope){
if(the_namespace contains identifier){
return found_entry;
}else{
return get_closesest_declaration(current_scope.parent, identifier, tag_or_identifier);
}
}else{
/* Must have reached file scope: No entry found. */
return NULL;
}
}
Pseudo-code For Tag Lookups
make_named_tag_predeclaration(scope, identifier, tag_type){
if(declaration for identifier already exists){
if(tag_type_matches()){
return declaration;
}else{
Error: Declared with wrong type of tag.
}
}else{
if(tag_type is "enum"){
Error: Forward declaration of enum is not allowed by the standard.
}else{
return setup_tag_predeclaration();
}
}
}
make_named_tag_definition(d){ ... }
parse_type_specifiers(...){
stuff_parsed = parse_stuff();
if(stuff_parsed is "struct", "union" or "enum")
stuff_parsed = parse_stuff();
if(stuff_parsed is an identifier)
/* Named tag. */
declaration = get_closesest_declaration(current_scope, identifier, tag_type);
if(declaration == NULL){
declaration = make_named_tag_predeclaration(current_scope, identifier, tag_type);
}
stuff_parsed = parse_stuff();
if(stuff_parsed == '{'){
/* Discard any previously found declaration, and make sure there is one in the current scope. */
declaration = make_named_tag_predeclaration(current_scope, identifier, tag_type);
make_named_tag_definition(declaration);
/* Note: Tag definition is only marked as completed after the matching '}' character is consumed. */
}else{
Error: Syntax error.
}
type_specifier = declaration
}else if(stuff_parsed == '{'){
/* Anonymous tag definition. */
type_specifier = make_anonymous_tag_definition(current_scope, identifier, tag_type);
}else{
Error: Syntax error.
}
}else{
Continue parsing: Not a type specifier.
}
/* Identifies the tag type, the scope level, and can point to either an incomplete or completed tag. */
return type_specifier;
}
Nested Structs And Unions
The above algorithm should work even for cases with nested struct or unions. It is important to realize that something like this:
struct foo{
struct abc{
union u {double d;} f;
} g;
};
is equivalent to this[2]:
union u {
double d;
};
struct abc{
union u f;
};
struct foo{
struct abc g;
};
As long as the above algorithm is handled recursively in the parser, then it should handle both cases properly. You should be able to handle anonymous tag instances too using a similar method, since you can say that this:
struct foo{
union {
int i;
double d;
} a;
};
is equivalent to this:
union { /* Represented internally as File Scope Union 1234 */
int i;
double d;
};
struct foo{
union <Anonymous File Scope Union 1234> a;
};
There is an important special case for C11 style anonymous non-instance members:
struct s{
int a;
union {
int b;
int c;
};
};
int main(void){
struct s x;
x.a = 1;
x.b = 2;
x.c = 3;
}
If I were re-designing the C language myself, I would say that the most consistent thing to do here is to make the above code declare an anonymous union tag at file scope, but since there are no instances created, it would just be ignored and the members 'b' and 'c' would not be accessible members of 'x'.
That's not what actually happens though, as the above compiles just fine. When you model your struct member namespaces, you will have to take special care to make sure that cases like this are taken into account:
struct abc{
int a;
union {
double a; /* Duplicate member error. */
double b;
};
};
A Special Case Of Incomplete Tag Types
In the above pseudo-code for modelling tags, you might find it odd that it treats every reference of 'struct foo' that fails to find an entry from 'get_closest_declaration' as a tag declaration. This allows the following cases of tag pre-declarations to work:
void main(void){
(struct foo*)0; /* If you delete this line. */
void (*f)(struct foo); /* This line will start generating warnings
because it will locally declare 'struct foo'
inside the function prototype. */
}
In the above algorithm, we would also search for a matching tag from an outer scope first before declaring a new tag in the current scope. If one was found, we would simply treat 'struct foo' as a reference to an earlier declaration and avoid making a declaration in the current scope. This brings us to the exception case:
struct foo;
The above case is completely different because it always declares an incomplete type in the current scope regardless of whether there is a matching tag from an outer scope. This is a nasty special case, because when you've parsed 'struct foo' you don't yet know whether it is appropriate to declare a new incomplete type in the current scope or not. You still need to parse (a possibly unlimited) number of other tokens:
struct foo{
int i;
};
int main(void){
struct foo /* <-- Does NOT declare a type struct foo in 'main' scope. */ f;
struct foo /* <-- DOES declare a type struct foo in 'main' scope. */;
struct foo /* <-- Does NOT declare a type struct foo in 'main' scope (gcc and clang) */const;
const struct foo /* <-- Does NOT declare a type struct foo in 'main' scope (gcc) */;
const struct foo /* <-- DOES declare a type struct foo in 'main' scope (clang) */;
}
Therefore, you will likely want to add a special case into whatever handles your 'declaration' grammar rule as the following pseudo-code demonstrates:
parse_declaration(...){
stuff_parsed = parse_stuff();
if(stuff_parsed is declaration_specifiers){
stuff_parsed = parse_stuff();
if(stuff_parsed is init_declarator_list){
....
}else{
/* No declarator: Check if this is special case of 'struct foo;'. */
if(is 'struct foo;' type declaration){
make_named_tag_predeclaration(current_scope, identifier, tag_type);
}
}
}else{
...
}
}
Other Information
There is still lots more than can be said, but since this article is getting a bit long, I'll leave it for the future.
If you found the above information interesting, you'd probably also enjoy An Artisan Guide to Building Broken C Parsers and The Magical World of Structs, Typedefs, and Scoping.
Conclusion
In this article, we reviewed a method for keeping track of variables, functions and tags at parse time. A tree-like model of scoping was presented, with the caveat that it is only valid in the context where an identifier is found. More specifically, declarations that appear after the use of a variable of the same name from an outer scope, can be incorrectly modelled if care is not taken. Pseudo-code was presented for performing a lookup of variable and tag types. A number of corner cases were presented related to forward-declarations of tags.
[1] C11 6.2.1 Scopes of identifiers
[2] Actually, there is a case where that re-arrangement is not equal in meaning, and here is that case:
struct foo{
struct boo{
void (*f)(struct foo);
} a;
};
is not the same thing as:
struct boo{
void (*f)(struct foo);
};
struct foo{
struct boo a;
};
try to compile these and you'll see why.
 How to Get Fired Using Switch Statements & Statement Expressions
Published 2016-10-27 |
 Buy Now -> |
 The Jim Roskind C and C++ Grammars
Published 2018-02-15 |
 7 Scandalous Weird Old Things About The C Preprocessor
Published 2015-09-20 |
 Building A C Compiler Type System - Part 1: The Formidable Declarator
Published 2016-07-07 |
 Building A C Compiler Type System - Part 2: A Canonical Type Representation
Published 2016-07-21 |
 The Magical World of Structs, Typedefs, and Scoping
Published 2016-05-09 |
 An Artisan Guide to Building Broken C Parsers
Published 2017-03-30 |
| Join My Mailing List Privacy Policy |
Why Bother Subscribing?
|