The Regular Expression Visualizer, Simulator & Cross-Compiler Tool
2020-07-09 - By Robert Elder
This article is part of Series On Regular Expressions. For more examples of regular expressions to visualize, check out this this list of Regular Expression Test Cases.
Your Regex:
String To Search:
Parse Tree |
Control Flow Graph |
Permalink:
The Regex As A C Program
Common C Code For All Regular Expressions
The C source code below is the common code that is required by any of the code samples that are generated above. Simply copy and paste the following code into a file called 'main.c' along with the dynamically generated code above in order to make a hard-coded program that will perform your intended regex search. Make sure the code below is passed before the dynamically generated code above. You can compile the code using this command:
gcc main.c
The code should compile without any issues and produce the executable program 'a.out'. You can run this program with this command:
./a.out
Note that code does not represent a fast implementation of the regular expression (in fact it's one of the slowest implementations possible). The goal here is to produce a program that is very short and easy to understand for educational purposes rather than to produce one that is fast and complicated.
#include <stdio.h>
#include <unistd.h>
#include <stdarg.h>
#include <stdlib.h>
#include <sys/wait.h>
#include <string.h>
#define GREEDY_BRANCH 1
#define LAZY_BRANCH 0
int split(int branch1, int branch2){
/* This function is just a fancy way to do a 'fork' call that will split this
process and execute 'branch1', then 'branch2' of the outer 'if' statement
where this function is called. It will also wait sequentially for 'branch1'
to finish before running 'branch2' rather than running both in parallel.
If 'branch1' returns 0 to indicate success, then 'branch2' will never run. */
pid_t child_pid;
pid_t wpid;
int status = 0;
if((child_pid = fork()) > 0)
while ((wpid = wait(&status)) > 0);/* Wait on child to finish in 'branch1'. */
else
return branch1;/* If this is child, return and contine in 'branch1'. */
if(WIFEXITED(status)){
if(WEXITSTATUS(status) == 0) /* Match found in 'branch1', exit the parent with 0. */
exit(0);
else
/* Continue on to check second branch... */;
}else{
printf("Unexpected Error Case.\n");
exit(1);
}
if((child_pid = fork()) > 0)
while ((wpid = wait(&status)) > 0);/* Wait on child to finish in 'branch2'. */
else
return branch2;/* If this is child, return and contine in 'branch2'. */
if(WIFEXITED(status)){
if(WEXITSTATUS(status) == 0) /* Match found in 'branch2', exit the parent with 0. */
exit(0);
else
exit(1); /* Neither branch found a match. */
}else{
printf("Unexpected Error Case.\n");
exit(1);
}
}
int matches_one_of_these_characters(char c, int num_chars, ...){
va_list arglist;
va_start(arglist, num_chars);
int i;
int found = 0;
for(i = 0; i < num_chars; i++){
int d = (char)va_arg(arglist, int);
if(c == d){
found = 1;
}
}
va_end(arglist);
return found;
}
int matches_this_character(char available, char required){
if(available == required){
return 1;
}else{
return 0;
}
}
char safely_get_character(const char * str, int offset, int pos, int str_len){
if(offset + pos < str_len){
return str[offset + pos];
}else{
exit(1); /* End of string reached.*/
}
}
int is_beginning_of_text(int position_in_string){
return position_in_string == 0;
}
int is_end_of_text(int position_in_string, int str_len){
return str_len == position_in_string;
}
Detailed Explanation
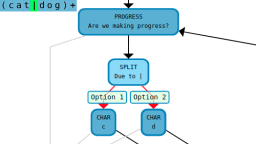
Above, you'll find an interactive visualization that you can use to simulate regular expressions. You can type any regular expression and the tool will automatically create two diagrams that correspond to your regular expression. Both of these diagrams are interactive, zoomable and include support for a fullscreen mode.
The first diagram is a parse tree. Constructing a parse tree is the first step that a regular expression engine will perform in order to decide what meaning each character will have.
You can click on individual nodes in the parse tree to highlight the corresponding character in your regular expression. You can also go the other way and click on individual characters in the regular expression to quickly find the corresponding characters in the parse tree. By reviewing how the characters are grouped together in the parse tree, you can gain insights about the meanings of individual characters and how they relate to each other in the regular expression.
The second diagram shows a control flow graph corresponding to your regular expression. This control flow graph illustrates the step by step process that is undertaken whenever your regex is matched against a piece of text. When attempting to match your regular expression, the process starts at the 'BEGIN' node and ends at either the 'MATCH' or 'FAILURE' node. Any path from the 'BEGIN' node to the 'MATCH' node corresponds to a piece of text that matches your regular expression.
Most of the nodes in the control flow graph correspond directly to one or more characters in your regular expression. You can click on nodes in the control flow graph to see the corresponding nodes highlighted in your original regular expression and the parse tree. Also note that clicking on characters in your regex will also highlight any associated nodes in the control flow graph.
It's difficult to truly understand how your regular expression works without seeing the decisions it makes when attempting to match a given piece of text. For this reason, every time you make changes to your regular expression, this visualization tool will automatically generate a piece of text that contains at least one match to your regular expression. If you want to review how the matching process work with your own customized piece of text, simply change the input value for the search string and the animation will update automatically.
The process of matching the regular expression starts at the 'BEGIN' node and continues by following the arrows to arrive at the nodes that actually do the work of the regular expression itself.
At the time of writing this sentence, all regular expressions that this visualizer tool supports are ultimately transformed into an control flow graph that consists of the following 5 types of nodes:
- 1) CHAR This node type checks for a specific character at the current position in the text that is being searched. If the character matches, we continue to the next node in the control flow graph. If it doesn't match, the control flow graph moves to the 'FAILURE' 'node'.
- 2) CLASS This node type checks for a class of characters at the current position in the text that is being searched. This node type effectively does the same thing as the first node type, except it allows for more than one possible character at the current position in the search text. If the current character in the text is among the list of acceptable characters specified by this node, we continue to the next node in the control flow graph. If it doesn't match, the control flow graph moves to the 'FAILURE' 'node'.
- 3) SPLIT This node type performs a 'split' operation. This is a situation where the regular expression matcher has a more than one possible path to continue through the control flow graph. In programming terms, this node effectively does the same thing as forking a process or splitting off work into two separate threads. This can also be implemented in a single thread by trying both paths one at time and pushing saved information onto a stack. In computer science theory, this node type should remind you of the difference between DFAs and NFAs.
- 4) ANCHOR This node type represents the commonly used 'beginning of string' or 'end of string' regular expression characters. This node is type is quite simple, as it simply checks whether the current position in the string is, respectively, at the first position, or the last position. If the check succeeds, we continue to the next node in the control flow graph. If it doesn't, the control flow graph moves to the 'FAILURE' 'node'.
- 5) PROGRESS This node type is necessary to avoid infinite loops in certain regular expressions that can include repetitions of possibly zero length strings. Without this node, there are cases where the control flow graph could potentially contain cycles that cause us to move around forever without making any progress. Each time a progress node is visited, it makes sure that we've made some progress in matching the regex since the last visit. If we have made progress, we move to the next node in the control flow graph. If not, the control flow graph moves to the 'FAILURE' 'node'.
You may find it surprising, but most commonly used regular expressions can be described in terms of the above 5 simple node types.
The primary purpose of this visualization tool is help you understand the precise meaning of the characters in a regular expression. Therefore, this the tool will also cross-compile your regular expression into a hard-coded C program that implements a search for the regex pattern that you specified. Each of the nodes in the control flow graph has a direct correspondence to several lines of C source code that are expressed below the two diagrams. You can click on nodes in the control flow graph to see which lines of code correspond to the node that you've selected.
Implementing A 'CHAR' Node
current_character = safely_get_character(str, offset, pos, str_len);
if(matches_this_character(current_character, CHARACTER_TO_MATCH)){
pos++;
}else{
exit(1);
}
For the implementation of a 'CHAR' node, we first use the 'safely_get_character' function to pick out the next character from the string being searched. The implementation of the 'safely_get_character' function is listed above in the 'Common C Code' section. This function is very simple since it just checks to make sure we're still within the bounds of the string that's being search, and if so, it returns character at the current position. If we're past the end of the string, we just directly exit the process. This corresponds to moving to the 'failure' node in the control flow graph.
After we've obtained the current character, we check to make sure that it matches the literal character that was specified in the regular expression using the 'matches_this_character' function. Here is the implementation of the matches_this_character function. As you can see, this function is very simple since it just checks to make sure that the current character in the string being searched is the same as the literal character that was supplied in the regex.
Implementing A 'CLASS' Node
current_character = safely_get_character(str, offset, pos, str_len);
if(matches_one_of_these_characters(current_character, NUM_CHARACTERS, CHARACTER_1, CHARACTER_2, CHARACTER_3, ..., CHARACTER_N)){
pos++;
}else{
exit(1);
}
The implementation of the 'CLASS' node is quite similar to the implementation of the 'CHAR' node. Just as with the 'CHAR' node, the C code corresponding to this node type will attempt to pick out the next character in the string being searched. If a character is returned, we pass it to the 'matches_one_of_these_characters' function which is also listed above in the 'Common C Code' section. This function is very similar to the 'matches_this_character' function, except this time, there is more than one acceptable character that can match at this position in the regex. The arguments that are passed to this function include, the current character in the string being searched, the number of character options to test for, and finally, the complete list of character options we want to check for.
The 'matches_one_of_these_characters' function looks a bit more complicated, but it's really quite similar to the 'matches_this_character' function. The difference is that for this function, we need to check though a variable number of arguments to see if the current character matches any of the characters that we supplied in calling this function. In C, accessing a variable-length list of arguments is accomplished by declaring a va_list, and using the special va_start, va_arg, and va_end macros.
Implementing A 'SPLIT' Node
if(split(BRANCH1, BRANCH2) > 0){
/* Try branch1 instructions first... */
}else{
/* Try branch2 instructions second... */
}
or
if(split(BRANCH2, BRANCH1) > 0){
/* Try branch1 instructions second... */
}else{
/* Try branch2 instructions first... */
}
The third node type is the 'SPLIT' node. This node type has by far the most complicated implementation as a C program. In fact, there are multiple correct methods to implement this node type as a C program. One way would be to explicitly use stacks allocated on the memory heap. Another way would be to implicitly use stacks allocated on the current thread's stack memory. Yet another way is to use process forking and goto statements, which is the method that will be illustrated here. This method produces code that is very slow and extremely inefficient, but it's also very short and simple which is exactly what is needed for an educational tool like this.
When the 'SPLIT' node type appears in the generated code above, it looks like a simple check of an if statement, but inside the implementation of the 'split' function is series of process control statements. The 'split' function starts by creating a child process to return and execute one of the branches in the outer if statement where 'split' was called. If that child ever reaches a 'failure' node by exiting the process with a 1, the parent process will be waiting here to detect this. The parent will then fork a second child process to continue as the opposite branch of the outer 'if' statement. If either branch returns a 0 to indicate that a successful match was found, the parent will detect this and exit with a return return code of 0 to signal success to any further parent process. If both branches fail to find a match, the split function will exit with a return code of 1 to indicate to any parent process that both branches of the search have failed.
Implementing An 'ANCHOR' Node
if(is_beginning_of_text(offset + pos)){
/* keep going. */
}else{
exit(1);
}
or
if(is_end_of_text(offset + pos, str_len)){
/* keep going. */
}else{
exit(1);
}
This node has the simplest implementation as a C program. As mentioned before, the anchor node occurs when using the 'beginning of text' or 'end of text' meta characters. It simply checks to see if the current position in the search text is at the beginning position, or the end position respectively. Note that anchor characters are often interpreted differently depending on the context, and they can either represent a position relative to the current line or a position relative to the entire text. The C code for the anchor nodes could be implemented slightly differently depending on which interpretation would would like them to represent.
Implementing A 'PROGRESS' Node
int progress_checks[1] = {-1};
/*...*/
if(pos > progress_checks[0]){
progress_checks[0] = pos;
}else{
exit(1);
}
The fifth and final node type also has a fairly simple implementation as a C program. All of the 'PROGRESS' nodes in the control flow graph can be represented as an array of numbers that describe how many characters were accepted by the regex during the last visit to each progress node. The progress values are all initialized to -1, and every time a progress node is visited, we check to see how many characters were matched the last time we visited that node. If more characters have been matched since the last visit, then we update the count for that node and continue. If not, the process is exited with a return code of 1 to send a failure signal to the parent process.
Conclusion
This concludes the review of all C source code that is required to implement a basic regular expression matcher. This code doesn't cover every possible regular expression feature, but it should hopefully make regular expressions a bit less mysterious.
References
The theoretical content discussed in this article was influenced heavily by the writings on Regular Expressions by Russ Cox. In particular, I recommend reading Regular Expression Matching: the Virtual Machine Approach as a supplement to this article. The ideas expressed in these writings reveal surprisingly deep connections between regular expressions, theory of computation and operating system development.
This article is part of a Series On Regular Expressions.
 Interesting Regular Expression Test Cases
Published 2020-07-09 |
 $20.00 CAD |
 An LL Grammar For Regular Expression Parsing
Published 2020-07-09 |
 Regular Expression Character Escaping
Published 2020-11-20 |
 How Do Regular Expression Quantifier Work?
Published 2020-08-18 |
 How Regular Expression Alternation Works
Published 2020-08-18 |
 Character Ranges & Class Negation in Regular Expressions
Published 2020-05-31 |
 Guide To Regular Expressions
Published 2020-07-09 |
| Join My Mailing List Privacy Policy |
Why Bother Subscribing?
|