Coming Full Circle On Code Duplication
2016-05-10 - By Robert Elder
An exploration of 3 stages you'll go through as a programmer.
Stage 1: Just Copy And Paste It
Everyone knows the story of the naive beginner programmer who starts with something like this:
void func(int * i){
if(cond1 || cond2){ /* Check teh value. */
*i = 0;
}
}
int main(void){
int i;
/* TODO: set i to 0. */
return 0;
}
and ends up doing this:
void func(int * i){
if(cond1 || cond2){ /* Check teh value. */
*i = 0;
}
}
int main(void){
int i;
if(cond1 || cond2){ /* Check teh value. */
i = 0;
}
return 0;
}
Of course, this leads to the inevitable combinatorial explosion in the number of branches as the program grows to be more complicated:
void func(int * i){
if(cond1 || cond2){ /* Check teh value. */
if(*i != 13){
*i = 0;
}
}else if(cond3){
if(cond1 || cond2){ /* Check teh value. */
if(*i != 13){
*i = 0;
}
}else if(cond4){
if(*i != 14){
...
}
}
}
}
int main(void){
int i;
if(cond1 || cond2){ /* Check teh value. */
if(i != 13){
i = 0;
}
}else if(cond3){
if(cond1 || cond2){ /* Check teh value. */
if(i != 13){
i = 0;
}
}else if(cond4){
if(i != 14){
...
}
}
}
return 0;
}
With experience, we come to realize that copying and pasting has 3 major problems: 1) It also copies bugs. 2) When you fix those bugs, you have to remember to fix all the other copies. 3) When you fail to do #2, you can create even more problems just by having code that does things two different ways, even if both are 'correct'. If you use 2 different ways of creating canonical identifiers, then you are no longer creating any canonical identifiers. This brings us to the ultimate and final solution to all programming problems:
Stage 2: Copy And Paste Is The Enemy
Of course once you become a real programmer, you realize that you should always try to re-use old code and write as little new code as possible. Inheritance is great way to accomplish this. When you add new complexity to your project, you can push it down toward your base class so other classes can take advantage of it too:
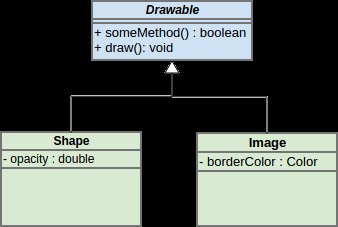
But then as the project grows, things become more complicated:
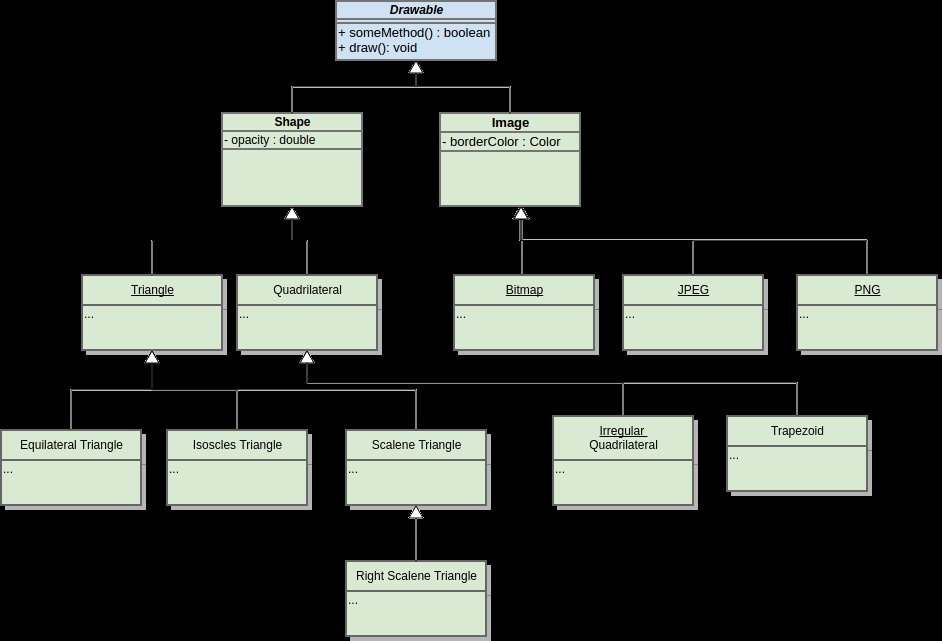
And now you've found yourself in a situation where one bug in the base class has a huge blast radius since it will affect every subclass. This effect is not limited to inheritance models since you can experience the same thing with utility functions, libraries, or any other type of coupling between modules.
Stage 3: Copy And Paste Is Your Friend
So now you're working on a project with thousands of modules written by people who don't work for your company anymore, and you don't even know what the project depends upon. You need to add something to a poorly written base class, and there are thousands of customers who depend upon this software. One service outage could cost millions of dollars, and it's not clear exactly how and what to change. What do you do? Just copy and paste!
|
|
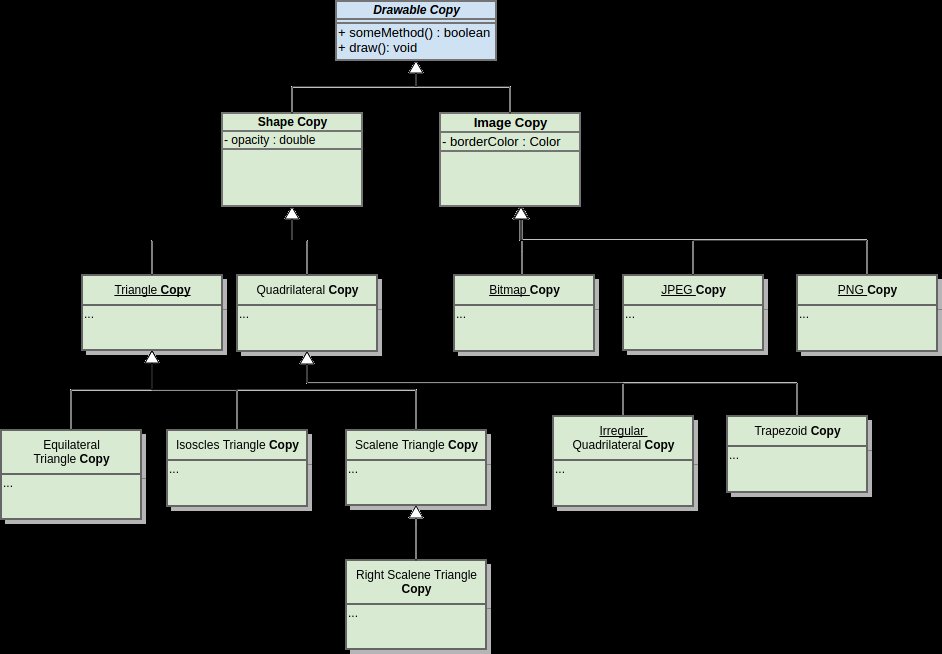 |
The goal here isn't to create a copy of the code for the long term, but to de-couple the customer dependent code paths from the the experimental new ones you're going to add. Ideally, you won't have to copy the entire project and can get away with just a few files/classes. Once you are sure that your new features works, and your project manager has stopped changing his mind about what he wants, you can refactor your new code path with the explicit goal of making it as similar as possible to the critical customer supporting version. This refactor phase is always dangerous because it's where you get comfortable and complacent that the code works (because it worked a minute ago). Doing this experimentation in a separate code path lets you be aggressive, productive, and have increased safety from breaking what customers depend upon. You can use various techniques to slowly turn on the new code path for increasingly larger numbers of customer until eventually, you can just remove the old code path.
In addition, you can independently make small adjustments to the customer supporting version with the intention of making the final merge easier. Ideally, these should be 'no-op' changes, meaning they have no observable effect for the customer, but they make the eventual merge easier. In-between these no-op changes you can run unit tests and do deployments without turning on the full experimental code path all at once.
This approach has a few advantages:
- The majority of dangerous refactoring activities can be done on a completely independent code path instead of doing it all on the critical code path.
- When you decide to de-duplicate the new code path back into the old one, you have a chance to reflect on how to minimize the number of code chances to your sensitive code path.
- During the period that you're hacking away on the new feature (which is always longer than you expect it will be), other developers are free to commit changes to the old code path without fear of getting caught in a hail storm of merge conflicts, and making the wrong assumptions.
- If the new code path does something really horrible the first time it is deployed, the number of customers affected will likely be smaller.
- Because you start by making small independent no-op changes to the customer supporting version of the code, if something does cause a customer issue the root cause is easier to isolate because it's not buried inside a monolithic commit that changed every file in the project.
- Verifying no-op changes is easier than verifying a change from one behaviour to another. A change can be a bug or a feature, but when a no-op changes something it is by definition a bug 100% of the time.
 The Regular Expression Visualizer, Simulator & Cross-Compiler Tool
Published 2020-07-09 |
 Buy Now -> |
 Why Is It so Hard to Detect Keyup Event on Linux?
Published 2019-01-10 |
 Myers Diff Algorithm - Code & Interactive Visualization
Published 2017-06-07 |
 Interfaces - The Most Important Software Engineering Concept
Published 2016-02-01 |
 Regular Expression Character Escaping
Published 2020-11-20 |
 How Do Regular Expression Quantifier Work?
Published 2020-08-18 |
 Overlap Add, Overlap Save Visual Explanation
Published 2018-02-10 |
| Join My Mailing List Privacy Policy |
Why Bother Subscribing?
|