Character Classes in Regular Expressions - A Gentle Introduction
2020-05-10 - By Robert Elder
This article is part of Series On Regular Expressions.
Introduction
This is the first article in a series that will train you to become a Regular Expression Master.
Knowing how to effectively use regular expressions can make you an extremely productive software developer. This is because regular expressions can be used to search for and manipulate pieces of text based on very specific patterns. Example use cases include, normalizing variable length phone numbers, parsing formatted dates, or finding words that have multiple correct spellings.
Unfortunately, most people consider the syntax of regular expressions to be too complicated to bother learning. This is partly because the exact syntax of a given regular expression can vary depending which programming language and environment you're using. Modern regular expressions also include a number of newer features that weren't included when they were first invented.
Your journey to become a regular expression master will begin with a trip back to the 1970s, when regular expressions were first invented and much simpler. We'll review the origins of the simplest possible regular expressions and understand how they became more complicated over time. In fact, let's consider the most basic possible regular expression. It's so basic that you don't even need to call it a regular expression because it's just a simple string search:
The animation above shows the C source code for a program that will match only the most basic regular possible expressions. This code isn't sophisticated enough to handle anything other than a simple string search yet. In this scenario, we're going to assume that we're living in the 1970s, back when every character was represented by exactly 8 bits, or one byte. This makes our analysis much easier, because every individual character that a regular expression could match is just one of the 256 numbers that can be represented by one byte. Since we're still living in the 1970s, newer multi-byte character encodings like Unicode haven't been invented yet, so they won't be considered. In our view, every piece of text is stored in the simplest way possible: As a sequence of bytes encoded in traditional ASCII.
This very simple search program starts by looking at the first character of the text we want to search. It compares this character to the first character of the string that we're searching for. Once the first character of our search pattern gets matched, the rest of the characters in the search pattern get compared against the text until a complete match is found. This works well for the simple search case shown here.
Multiple Searches At Once
Sometimes one simple string search isn't enough. In the following example, the text that we're trying to search includes two different but common spellings of the word 'gray'. The spelling of 'gray' with an 'a' is more common in American English, whereas, the spelling that uses an 'e' is more common in British English. This means that if we want to search a document that contains both spellings using only simple string searches, we'd need to search the entire document twice: Once for each different spelling of 'gray'.
Introducing Character Classes
A more effective way would be to search for both spellings at once. We can easily do this by changing the code in our search program to check each position in the text for a list of characters, instead of just expecting a single matching character to appear at each position every time. We can also invent a special notation for describing the search string: Whenever the search string includes a list of characters inside a pair of square brackets, treat the square brackets and whatever's inside them to mean "match exactly one character that's inside these brackets".
By the way, we've just invented one of the most fundamental concepts in regular expressions: character classes.
Let's review how the updated search process works: Just as we did before, we start by looking at the first character of the text, and compare it to the first character of the search string. Once we find a match, we continue comparing the characters in the text against the next character in the search string. What's different about this updated version can be seen when we get to the comparison of the third character: We now have another inner loop that checks all of the possible matches for the third character. If we find the current character from the text in the list of acceptable characters at this position, we consider that a match. If not, the matching process will fail and we re-start matching the start of the search string again just as we did before.
It's worth pointing out that you could consider every literal character in a regular expression as though it belonged to some character class. Using this perspective, every regular character would belong to a class with only one option, so it would be tedious and ugly to write square brackets around every single one when defining the regular expression.
[g][r][ae][y]
Using Multiple Character Classes
One great thing about using character classes is that we're not limited to just having a single character that has multiple possible matches. Without making any new changes to the structure of our code, we can change the first character of the word 'gray' to also use a character class so that it can match a capital 'G' character as well. This way, we can match 4 different spellings and capitalizations of the word 'gray' at once.
More General Uses For Character Classes
Character classes can also be useful for specifying other types of characters as well. Imagine that you wanted to search a student's book report for references to book chapters, but you don't know in advance which chapter numbers the report would reference. You can simply list out the characters 1 through 9 in a character class and this will allow you to find the first digit of the chapter number. For chapter numbers larger than 10, this regex will only pick out the first digit and ignore the rest, but we'll assume the book only has 9 chapters for this example.
A similar use case for character classes would be if you're in the process of editing a paper or a book. During the editing process you'd like to make sure that any reference to a figure references the correct image. Each figure in your document is assigned a lower-case letter of the alphabet, so you'd like to find every occurrence of the word 'figure' followed by a single letter from 'a' to 'z'. You can do this with this regular expression:
Observe how our search program will now check for both an upper and a lower case 'F' character in the word 'figure'. It also checks the entire alphabet for the letter that identifies the figure too.
Searching For Formulas With Character Classes
You're not limited to just using letters and numbers in character classes either. You can also use punctuation and symbols. For example, here is a regular expression that will match any addition or multiplication between a pair of two-digit decimal numbers.
It will even handle inconsistent uses of a period or comma for the decimal point.
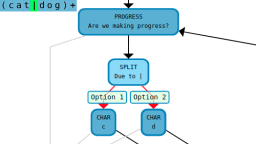
Matching 'a' and 'e'
Using symbols is where most people get confused when learning regular expressions. In order to make things as clear as possible, this guide will make use of diagrams communicate exactly which individual characters will be matched by a given regular expression. For example, here's the first character class we reviewed when searching for the word 'gr[ae]y':
Being precise about this concept is extremely important. For all of the examples that we've seen so far, the characters that you see described inside the square brackets look exactly the same as the actual characters that get matched in the text. As we're about to see, this is not always the case.
Incorrectly Matching ']'
For example, let's say we wanted to create a character class that matched a closing square bracket. You might be tempted to try writing this:
But this doesn't work! It doesn't match any characters at all! You can probably already see why this is such a special case: The character that we want to specify in this class is one of the same characters that are used to describe the character class itself. In this case, the regular expression parser thinks we want to end the current character class as soon as it sees the first closing square bracket character. This leaves us with an empty character class that doesn't specify any character options at all, which is not very useful! By the time it sees the second closing square bracket character, the character class that we were attempting to describe has already been closed, so the regular expression parser just assumes that this must be a literal character since there is no other meaningful interpretation.
If you try to match this regular expression against a piece of text, you'll find that it never matches anything! This makes sense since our regular expression gets interpreted as a sequence of two characters. The first character must be one of the characters listed in the empty character class, so it can never match any character. The second character must be a closing square bracket, but it doesn't matter since the first character can never be matched.
You're probably wondering "Why would anyone ever want to specify an empty character class like this? Isn't that completely pointless?" The answer is "You're right, it is pointless." In fact some Javascript linting software will warn you if you try to write a regular expression with an empty character class:
If you try to write an empty character class with grep, it will give you an error message:
echo "abcdef" | grep "[]"
grep: Unmatched [ or [^
You'll get a similar kind of error in the Ruby programming language:
ruby -e 'puts "abc".scan(/[]/)'
-e:1: empty char-class: /[]/
Now that we know the wrong way to specify a closing square bracket inside a character class, what's the right way?
Correctly Matching ']'
The answer is to put a backslash character in front of the closing square bracket character. The act of using a backslash in front of a character to get rid of its special meaning is called 'escaping' the character.
Incorrectly Matching '\'
The next problem you're likely to encounter with character classes is when specifying a backslash character inside a character class. If you try to specify a backslash this way:
You'll get an error message about an invalid regular expression. This shouldn't come as a surprise since we just saw how a backslash character will 'escape' a closing square bracket to remove its special meaning.
Correctly Matching '\'
The proper way to specify a backslash character is by using another backslash character to escape it:
What Other Characters Need Escaping?
You might be wondering what other special characters are there that also need escaping in a regular expression? This turns out to be a complicated question. As mentioned before, different programming languages and environments have different levels of support for all the different features of regular expressions. In fact, character escaping turns out to be one of the aspects of regular expressions that varies the most between programming languages or environments.
To keep things simple, this guide will focus on a middle-ground approach that explains what is true almost everywhere, but do keep in mind that some languages will have exceptions.
There are many different escape characters, and the rules for escaping are different depending on whether the character is inside or outside of a character class. First, we'll review what characters need to be escaped inside a character class. There are only 5 characters that have a special meaning inside a character class, and we've already reviewed two of them:
- [ Purpose: Start of character class.
- ] Purpose: End of character class.
- \ Purpose: Escaping.
- - Purpose: Intro Character ranges.
- ^ Purpose: Class Negation.
Escaping '[' Isn't Always Necessary
Since we already saw how the closing square bracket requires escaping, it shouldn't come as a surprise that the opening square bracket character often does too. Unsurprisingly, if we put a backslash character in front of an opening square bracket in our character class, this allows us to specify the expected character. However, you may find it surprising to know that with Javascript's regular expression engine, escaping the opening square bracket character in a character class is optional while escaping the closing square bracket character is mandatory.
This is just one example of the many quirks that exist between different regular expression engines. The reason that Javascript allows you to use an un-escaped opening square bracket inside a character class is probably related to the fact that it also doesn't allow you to put character classes inside each other. Since one character class can't appear inside another in Javascript, the regular expression parser just assumes that any opening square bracket found inside a character class must represent a literal character.
Some programming languages such as Java, Ruby or .NET support a regular expression feature that does allow nested character classes. This feature is called character class unions, subtractions, or intersections. Whenever this feature is supported, escaping an opening square bracket in a character class is mandatory. If you just want to keep things simple, stick to always escaping an opening square bracket when specifying a literal character whether you need to or not.
Conclusion
In the next section, we'll review the last two special characters that can appear inside a character class. This will gives us a fairly complete understanding of how character classes work, and put you well on our way to becoming a regular expression master.
This article is part 1 of a Series On Regular Expressions. You can read Part 2 on Character Ranges & Class Negation here.
 The Regular Expression Visualizer, Simulator & Cross-Compiler Tool
Published 2020-07-09 |
 Buy Now -> |
 Regular Expression Character Escaping
Published 2020-11-20 |
 How Do Regular Expression Quantifier Work?
Published 2020-08-18 |
 Interesting Regular Expression Test Cases
Published 2020-07-09 |
 How Regular Expression Alternation Works
Published 2020-08-18 |
 Character Ranges & Class Negation in Regular Expressions
Published 2020-05-31 |
 Guide To Regular Expressions
Published 2020-07-09 |
| Join My Mailing List Privacy Policy |
Why Bother Subscribing?
|