Interfaces - The Most Important Software Engineering Concept
2016-02-01 - By Robert Elder
Last Updated: Sept 29, 2016
Synopsis
An interface can be thought of as a contract between the system and the environment. In a computer program, the 'system' is the function or module in question, and the 'environment' is the rest of the project. The interface formally describes what can pass between the system and the environment. An 'implementation' can be defined as the system minus the interface. Interfaces in languages like Haskell can be extremely specific, or very non-specific like in Python. The types of interfaces used can affect the amount of technical debt that is created (a mathematical formula is provided), and programmer productivity. A method for quantifying and comparing interfaces is proposed. Based on these comparisons, you can make a number of observations about the way a language or tool is used.
Read the comment thread on Hacker News.
Overview
The most important concept in software engineering is the concept of an interface. This article is not about interfaces in Java, it is about interfaces in software design, and to a lesser extent, interfaces anywhere in the universe. There are many other important concepts used in software development, but I would argue that many of them actually end up relating back to why interfaces are so important. In this article, I will discuss:
- What is an Interface?
- An Interface as a Contract
- What is a 'Module' or 'Abstraction'?
- Abstraction Leaks
- A Method for Comparing and Quantifying Interfaces
- A proposal for how to treat interfaces with respect to patents and copyright.
- Why people still use the command line.
- Why it was the right move for Twitter to start with Ruby/Rails, then re-write their code in Scala.
- Why Java and C++ are used so much in enterprise software.
- An attempt at mathematically quantifying how technical debt scales, and why it only becomes obvious in large projects.
- Why Python is so popular, specifically for newer programmers.
- How to effectively cut corners, while minimizing technical debt.
What is an Interface?
In university we learned of a couple succinct definitions for what an interface is that I really like:
An interface is a contract between the system and the environment.
or alternatively
An interface is the intersection between the system and the environment.
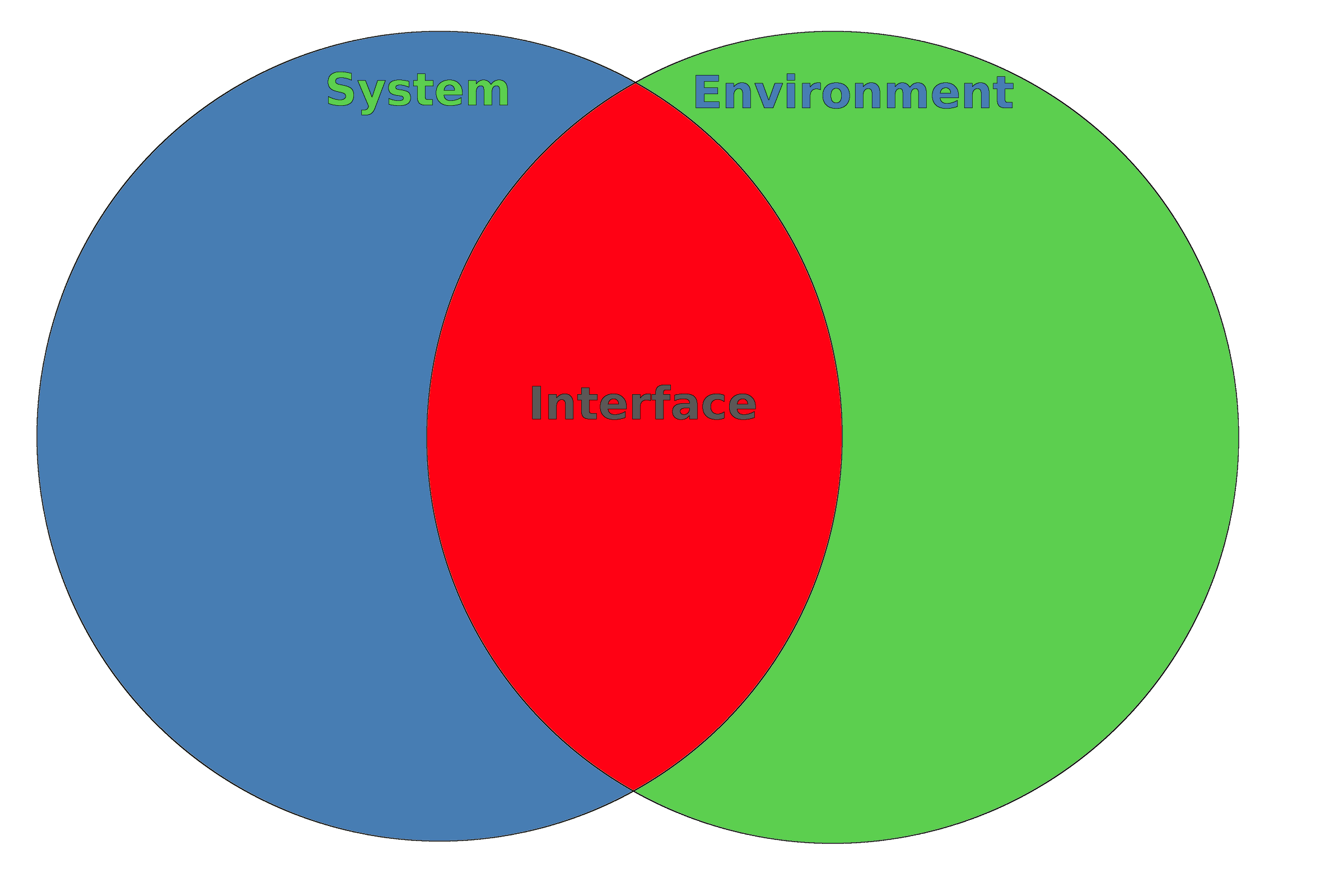
The intersection definition fits well when the 'system' is actually a physical object. The above definitions are very abstract, so let's go directly to a specific example of someone typing on a keyboard:
 |
 |
In the above example, the system represents the laptop computer as a whole, the environment is the person's hands (and any nearby cats that like to step on keyboards). The interface, therefore, must any part of the interaction between the hands and the computer that is not exclusively attributable to one or the other, but can only be attributed to both. Normally we think of hands and keyboards as being distinctly separate, so the precise boundary of the interface in this case is up for philosophical debate. It is up to the reader to decide whether they consider the entire keyboard, or just the individual atoms that come in contact with the fingers or keyboard to be part of the interface. You might be wondering how this example can relate to the definition of an interface as a contract: The "contract" in this case is the convention that we all spent much effort learning back when we had to program our brains with all the muscle memory to know where all the keys are. There are also more subtle aspects to the contract, like the fact that pressing a key and holding it down has a different meaning than pressing it quickly and releasing.
This is a nice bit of philosophy, but what does it have to do with writing software? Well, interfaces in programming are all around us, even if you're not aware of it. If you're a Java programmer you explicitly name them for what they are, but they also exist in other languages like C. Let's consider the interface of the function 'add_numbers' in the following example:
unsigned int add_numbers(unsigned int, unsigned int);
void other_function(void){
add_numbers(3,4);
}
unsigned int add_numbers(unsigned int a, unsigned int b){
return a + b;
}
int main(void){
add_numbers(9,99);
return 0;
}
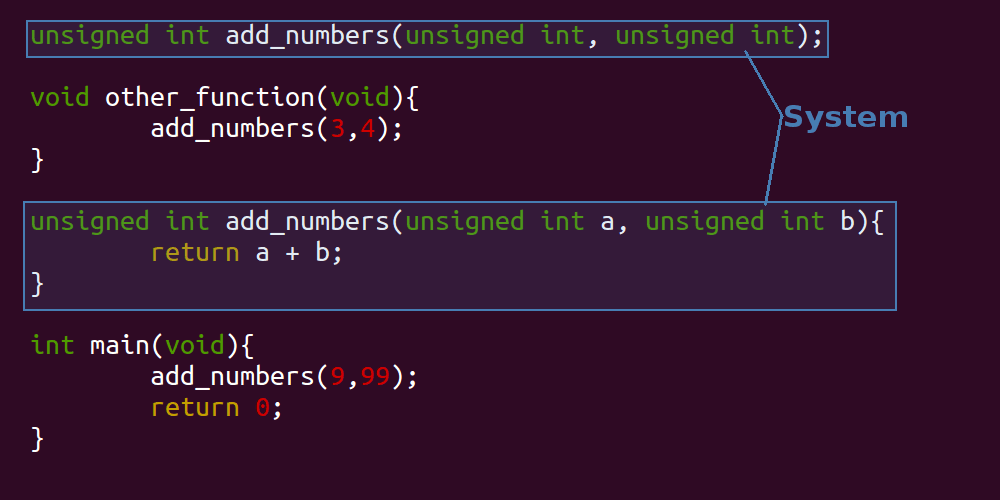
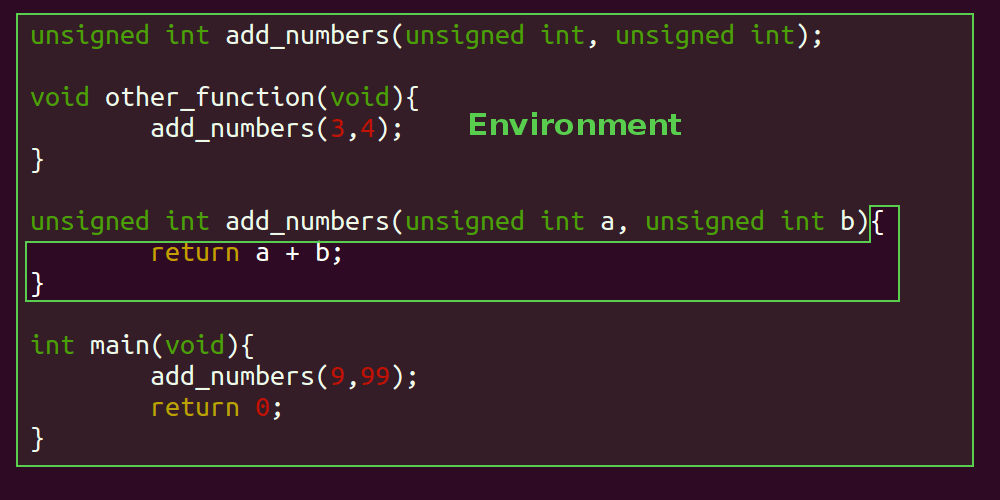
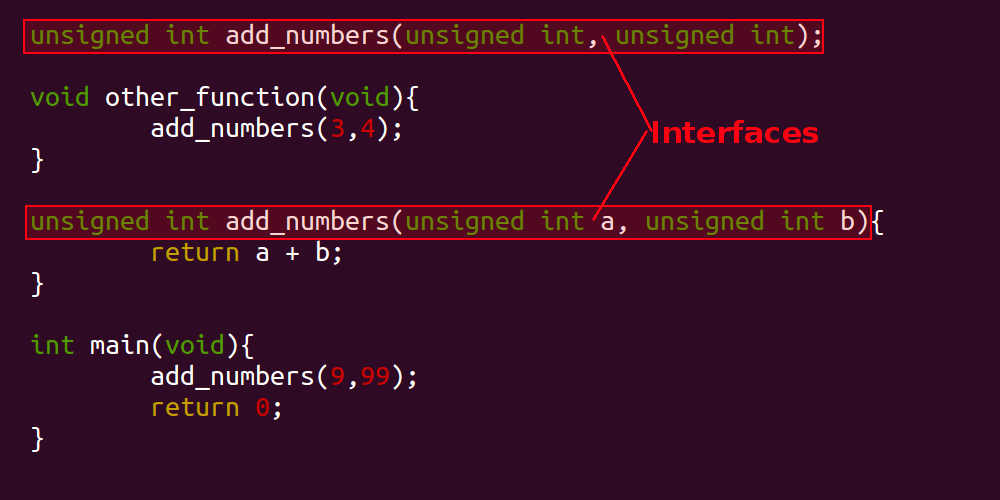
Let's apply the same highlighting technique to describe the environment, the 'add_numbers' system, and the interface:
 |
 |
 |
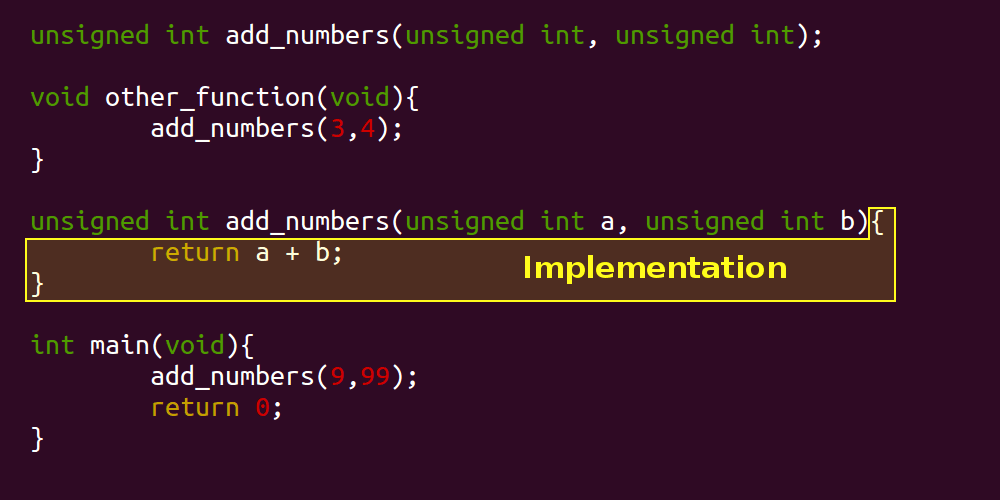 |
In the above illustrations, the 'system' in question consists of the 'add_numbers' function. You would be correct to say that the main method, or the 'other_function' method could also be considered an individual system, however for simplicity the images above have considered the 'add_numbers' function as a system in isolation. It would also be reasonable to consider the invocations of the 'add_numbers' function to be part of the interface too. Note that we've added a fourth idea: an 'Implementation'.
Defining The System And The Environment
I haven't yet defined the term 'system' or 'environment' yet, so let's review what I mean by these terms: The system is easy to define: It is whatever useful thing you're working with. It could be your laptop computer, a computer program, the door to enter your house, or a small piece of source code. What I mean by environment can be defined in terms of the system: First, consider the environment to include the entire universe. Now, take as much of the system as possible out of what you consider to be the environment, but stop once you've reached the point where removing anything further would prevent the environment from interacting with the system through its shared boundary to the system in question. So if you consider the laptop example, we could still use the laptop if its internals were made differently (but had the same functionality), but once we start changing the keys around or the screen, then we would start having problems interacting with it.
Impossible Interfaces
A worth-while question is: "Is it possible to describe an interface that can't actually have an implementation?" I would claim that you can, and that this would occur if your interface has contradictory claims in its description. For example, if you defined an interface that asserted "This function does not return 0." and "This function returns 0.". There is no possible implementation that is consistent with both of these assertions. You are, however, free to make claims that you won't be able to deliver on when you describe the interface.
Defining The Implementation
It is difficult to discuss interfaces without making reference to implementations, so let's go ahead and try to formally define what an implementation is:
An implementation is the system minus the interface:
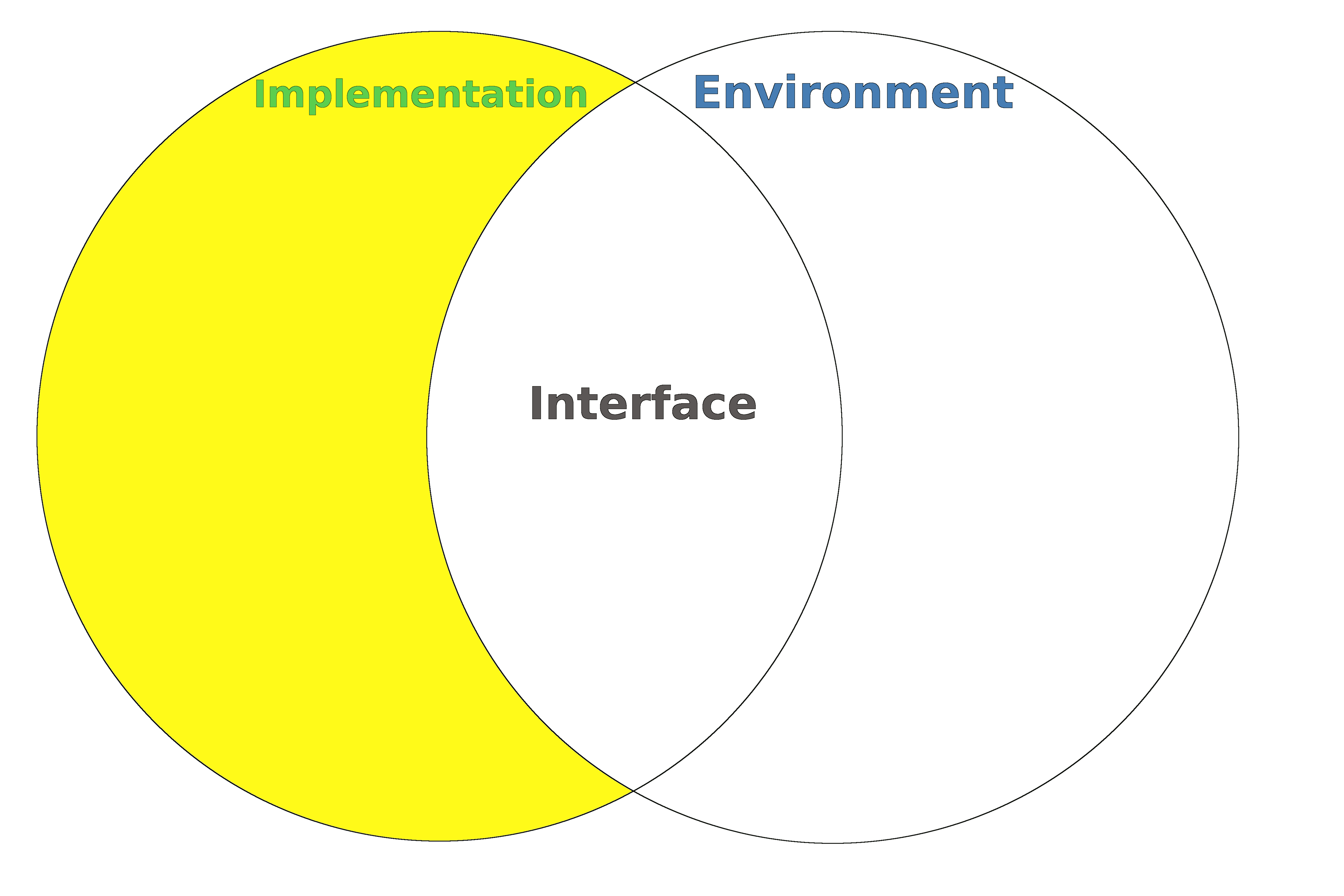
Please note that I've never actually heard of (or don't remember) anyone else defining an implementation this way, but it seems like such an irresistible extension of the set based definition of an interface and it has a couple other benefits I'll discuss shortly. If you're a poor student studying for an exam, your professor will probably have never heard of this definition. I also wouldn't be surprised if this definition was in conflict with some Object Oriented Programming taxonomy, but even it does, I don't plan to change it. Let those crazy OOP people change their textbooks to match my definition.
Defining implementations this way leads us to other reasonable conclusions: When we talk about interfaces on physical systems, we typically think of the 'system implementation' as the entire physical object, and it would be unnatural to consider the 'real' system implementation to exclude the buttons, screens or any other physical part. This pushes us to consider the interface to include as little as possible of the physical system, and represent more of a convention. It is almost as if an interface were just a set of promises, guarantees, or some kind of ... CONTRACT BETWEEN THE SYSTEM AND THE ENVIRONMENT!
An Interface as a Contract
Let's consider the interface to the function 'add_numbers' in the previous example as a contract, and see what it guarantees:
- 'add_numbers' is a function that exists.
- 'add_numbers' takes exactly two parameters, both of which are 'unsigned int's.
- 'add_numbers' returns exactly one 'unsigned int'.
The interface for this function does not say anything about
- Whether 'add_numbers' will ever halt.
- The asymptotic run-time complexity of 'add_numbers'.
- The quantity of free memory required to run 'add_numbers'.
- What the implementation of 'unsigned int' really is.
- Side effects (like allocating memory, and modifying global variables)
The interface to 'add_numbers' described above is known as a function 'prototype', and in earlier versions of K&R C, there was a weaker form of describing interfaces:
unsigned int add_numbers();
Defining an interface as a "contract" is very convenient for programming since most programming tasks simply amount to defining and requiring sets of axioms. Post-conditions, and pre-conditions are all guarantees about certain properties or behaviour. Before two parties engage in doing business together, they ought to have a contract prepared. The contract spells out what the deliverables are, how much money is paid, and when. Other topics like early termination, indemnification, expenses are all lain out in advance. When the contract is breached, a court or an arbitrator can resolve the situation, but if you forget to define something in the contract, then unexpected surprises are more likely. In a computer program we have the same thing: Modules and functions specify what they want, and (sometimes) what they will return. A breach of this contract will result in a compile error, a run-time error, program fault, build system or linter failure or even your manager yelling at you. I would go so far as to say that the concept of defining an interface as a "contract" is not even metaphorical. It really is the same concept as a business contract, even thought a business contract is typically not as detailed.
Patents, Copyright and Interfaces
This section does not consist of legal advice and may even be in contradiction with existing law, all statements herein are the opinions of the author.
In the previous section, I stated that I would consider an interface to literally be a 'business contract' between two entities, and I emphasized that I don't consider this to be a metaphor. I believe this interpretation is one that appeals to the concerns of both computer scientists and also to legal professionals who aim to protect creative works.
Should an interface be patentable? Using the definition included in this article, that an interface is a contract between the system and the environment, I do not believe that interfaces should be patentable, and so far the existing case law seems to agree with me. Keep in mind, however, that the word 'interface' is very generic, and is often used in a way that is different than how I have defined it in this article.
Should an interface be copyrightable? Using the definition included in this article, that an interface is a contract between the system and the environment, I do believe that the "Source Code" of an interface should be copyrightable. Furthermore, the copyrightable aspects of an interface should extend no further than the point just before they begin to cover the aspects of an interface that make interfaces so special. The copyright should cover only the medium (source code or handwritten copy), but not the guarantees or constraints. If any guarantees or constraints of the interface become inseparable from any part of the medium, then those parts of the medium should be disqualified from copyrightability. I'll propose a simple test that could be applied to determine if something is not copyrightable:
If you consider a set of attributes of an interface that you'd like to consider copyrightable, given any conceivable third-party piece of software that successfully uses the interface in question in any way, it should always be possible to build some drop-in replacement that declares and implements the same interface and is successfully used by the third-party software without any modification to the third-party software, and without infringing any copyrights. If every possible drop-in replacement would cause infringement or require that the third-party software be modified or regress in functionality, then the chosen set of copyrightable attributes are too aggressive must be reduced.
I believe the above test would be appropriate to test for patentability as well. Note that this test would only determine if something is not copyrightable or patentable. It would say nothing about conclusively determining whether it is copyrightable or patentable. Finally, the above test is just my opinion, don't confuse it with actual law.
An important thing to point out in relation to the above test, is that any criteria that could be considered part of the interface in one language, may not be part of the interface in another language. For example, in Java the order in which functions are declared does not affect program execution. If you were tempted to casually say 'the order of functions in the file never matters', then you would be incorrect if you consider the following python program:
def foo():
print("asdf")
def foo(abc):
print(abc)
foo("lol")
Giving consideration to the legal aspects of interfaces prompted me to go back and take a look at the famous Oracle Vs. Google case. The provided link includes details of the case that would be interesting to software developers, so that's what I'll draw on for my analysis. In summary, based on what I see, I can't find a reason to disagree with the outcome in favour of Oracle. That's not to say that I support it, since the publicly available case details that I can find are fairly sparse.
I think the concern among most software developers was that the outcome of the case might set a precedent that would allow copyright or patents to cover parts of interfaces that would cause the above test I proposed to fail.
The outcome of the case rested on the district court's finding that 'the "structure, sequence and organization" of an API was copyrightable.' As I mentioned above, I don't think there is a problem with this, as long as the definition of "structure, sequence and organization" does not cause the above test to fail. Here are a few quotes from the linked article that are key:
"The district court concluded that 'there is only one way to write' the declarations to interface with Java. If true, the use of identical declarations would not be copyrightable. However, except for three of the API packages, Google did not dispute the fact that it could have written its own API packages to access the Java language." and finally "Google conceded that it copied the declarations verbatim."
It would seem that the district court made the right decision in concluding that the intrinsically unique properties of an interface are not copyrightable, but Google also admitted to copying declarations 'verbatim'. If 'verbatim' can be take to include literal copy and pasting, that includes non-functional aspects like white space, and spelling mistakes in comments, then I think it would be very reasonable to consider this as copyright infringement. The non-copyrightability of an interface does not need to prevent an individual artistic expression of an interface from being copyrighted.
My knowledge of this case only comes from what I can read online, but it would appear to me that Google created verbatim copies of Java source code which happened to include interfaces. Google themselves appears to have been been of the opinion that their use of Java required licensing, because prior to 2010 Google pursued licensing deals with Sun to license the use of Java. After Sun was acquired by Oracle, the licensing negotiations fell through. The fact that Google was pursuing licensing deals that didn't come to fruition, but continued using 'verbatim' copies of code doesn't seem to help their case. I suspect that Google's lawyers may have known they had a weak case, and so they attempted to use a defense related to the very legitimate claim that interfaces should not be copyrighted, and hoped that the source code representation of an interface, and the more philosophical concept would become conflated, allowing them to win the case.
What is a 'Module' or 'Abstraction'?
When I think about a 'Module' I think of one of those 'shape sorter' toys for children, where you can place different shaped blocks through holes that consist of squares, circles, triangles etc.
The reason I think this representation applies so well is because it clearly emphasizes the importance of the boundary of the module, and how it interfaces with the rest of its environment. Furthermore, the interface of the cube above imposes very strong constraints about how the external world can interact with what is inside. You can't go around the interface, so if you want to interact with it, you must do so through the means it exposes to you. Finally, there is nothing in the cube, but we actually don't care, because it's not what's on the inside that counts (sorry cube), it's the interface that is exposed to the world.
Another example I really like is that of a cell and its membrane: Features on the cell surface like transport and receptor proteins only permit certain things in the extra-cellular matrix to influence what happens inside the cytoplasm according to very specific rules:
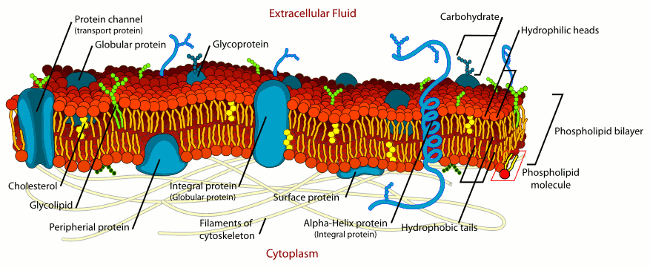
In the context of this article, I will refer to 'modules' and 'abstractions' as if they were the same concept. The dictionary definition of these words is certainly not the same, and even between programming languages these concepts have different meanings. The key properties I'm interested in are that both of them can be though of as a 'system' as we've been using the term in this article: Abstractions and modules can be thought of as something consisting of an interface, and an implementation. You could think of an individual function in C as a module, a 'module' in Python, a class or package in Java. Anything that has some kind of externally presented interface, and some 'hidden' implementation. Note that the 'hiddenness' of the implementation can be imposed by the rules of the language, or even just by convention of the programmer.
Abstraction Leaks
As far as I can tell, the idea of an abstraction leak can be traced back to an essay by Joel Spolsky. There are a few good examples of specific abstraction leaks in the essay, but I'd like to add one of my own: The concept of a 'map' is very common in programming, and represents a data structure consisting of key and value pairs. An important constraint that the map guarantees is that all map keys must be unique: Trying to write a new value to a given key either results in an error, or overwriting the previous value for that key. The result is never to have duplicate keys. An extremely common programer requirement is to want to iterate over all the keys of the map. Since ordering of keys is not necessarily a guarantee maps provide, you might wonder what order the keys will be in when you iterate over them? Well, the ordering is not defined, because the map interface does not provide any guarantee of ordering. Therefore, any ordering is considered acceptable, but in practice the keys are likely to be sorted in some way. Why would they be sorted? Well, sorting happens to be an efficient way of organizing the data. It can make things like checking for pre-existing keys easier.
Iterating over sorted data can produce very different results than iterating over random data. For example, if you're trying to find the minimum number in a list:
min = null;
list = map.getMapKeys();
for (item in list){
if ( min == null ){
min = item
}else if (item < min){
min = min; /* This line has a bug */
}
}
The 'else if' branch will never execute if your data is sorted in ascending order, and even if you do randomised input testing, your program will never uncover the problem with this line. This is a huge problem, because if you swap the map implementation out for another one that doesn't return sorted keys, then your code is suddenly going to start running the buggy code path. At this point, you've complete forgotten about this code, and it is hidden inside a huge monolithic project.
I'm going to propose my own definition of an abstraction leak for use later in this article:
An abstraction leak exists when it is possible for an implementation to affect the environment in a way that was not agreed upon in the interface.
Using this definition, it would seem that nearly every abstraction is leaky, because specifying every environmental effect in the interface is only practical in the most rigorous mathematical systems. For physical systems, you could probably also make a connection to Gödel's incompleteness theorems here. The idea that most abstractions are leaky is not unfounded since that is essentially what Joel Spolsky implies with his 'The Law of Leaky Abstractions':
"All non-trivial abstractions, to some degree, are leaky."
Well if every abstraction is leaky why bother talking about it? Problems only occur when a part of the environment begins to rely on one of these unspecified environmental effects that originated from the system in question. These are the problematic abstraction leaks that everybody talks about.
This has far-reaching consequences, not only for casual bugs but also in the security domain. There is one well-known phrase related to the security of physical systems, where unintended effects from the system leak into the environment in a way that compromises its security: A Side-channel attack. Combining this with the claim that all abstractions are leaky would give the following conclusion:
Every physical implementation of a cryptosystem is vulnerable to a side-channel attack.
Given what we've discussed above, it is not unreasonable to extend this idea to include not only physical implementations, but also emulated ones as well.
Quantifying and Comparing Interfaces
As we saw above, interfaces in C specify things like the return type, and the number of parameters that can be passed into a function. But what do interfaces in Python specify? Note that I'm using the term 'interface' in a way that is consistent with this article, which is likely more general than any literature you've read before on 'interfaces' in Python.
def add_numbers(a,b):
return a + b
print(add_numbers(3,1))
print(add_numbers("abc","def"))
In Python you don't have to specify the types on the interface to a function. This has the benefit of making the function easier to define and invoke because there is less information to specify, and the disadvantage of less constraints that can be checked ahead of time (to detect possible programming errors).
I think there is something to be said about comparing and quantifying the different characteristics of an interface in terms of how many ways you can send information through them. This could be done for a specific interface, but also from the perspective of all interfaces that can be specified in a given programming language. It may also be useful for comparing the safety of specific interfaces within the same language. For the 'add_numbers' example in C, let's consider how much information we can send both through, and around the interface through abstraction leaks:
Information Through C Interface
|
Information Around C Interface
|
And these are the number of things that can be communicated through the python interface to 'add_numbers'
Information Through Python Interface
|
Information Around Python Interface
|
Now if you take a look at the types of interfaces we can describe in Haskell (Thanks to James Hudon for reviewing this, since I barely know any Haskell):
add_numbers :: Int > Int -> Int
add_numbers 3 4 = 7
main = print (add_numbers 3 4)
With the above Haskell code, the interface 'add_numbers' can accept the following information:
Information Through Haskell Interface
|
Information Around Haskell Interface
|
For a specific interface in a given language, you can quantify a couple different things:
- The number of unique ways you can communicate information through the interface
- The number of unique ways you can communicate information around the interface through abstraction leaks
From the perspective of programming languages you can also make observations about
- How restrictive the language lets you be about how much or how little information goes through an interface
- What tools the language provides you with for preventing communication around the interface.
If you extend the same type of analysis to other interfaces, like for example graphical user interface where you can change directories:

Information Through GUI
|
Information Around GUI
|
And if you review the same task of changing directories performed on the command line using 'cd':
Information Through GUI
|
Information Around GUI
|
For the information sent through GUIs and the command line, there is actually another piece of data that I didn't include in the above tables: The amount of noise in the signal. If you consider how hard it is to exactly repeat a sequence of keyboard strokes (key by key) versus a sequence of mouse movements (pixel by pixel), you'll note that there is always way more error in the data you get from a mouse movement or click versus a keyboard stroke. GUIs compensate for this by making the semantics they accept more non-specific. Can you imagine if the clickable area on "OK" and "Cancel" buttons was only 1 pixel wide? In addition, this analysis can get even more complex when you consider how the error rates change for differently abled individuals.
Now that I've reviewed one possible way to quantifying and comparing interfaces, I'll make a few extrapolations from these examples and my own personal experience:
- Human beings tend to prefer interfaces that aren't very specific about the information they accept, especially when they are unfamiliar with that interface
- Interfaces that aren't very specific about what information they accept are prone to being misused.
- Catch-all interfaces that accept large amounts of information are seen as powerful, but are often misused.
- Humans tend to communicate information around an interface when communication becomes tedious.
- Communicating around an interface through abstraction leaks is very prone to undesirable surprises.
Leaky and Specific Interfaces
I'm going to make a lot of observations based on the analysis in the previous section, so I'll define a couple terms for the sake of clarity:
A Leaky interface exists when the interface is prone to being ignored during any communication between the system and the environment.
An interface is Specific if is has a relatively small number of possible inputs and outputs.
For more details on Leaky interfaces, consult the section on abstraction leaks. A good example of what I mean by a Specific interface would be piecewise defined functions, defined only for a very small number of inputs.
If you can meaningfully quantify how 'leaky', or 'specific' interfaces are, I think it is worth defining a spectrum where interfaces that are very specific and non-leaky are on one end, and non-specific and leaky interfaces are on the other:
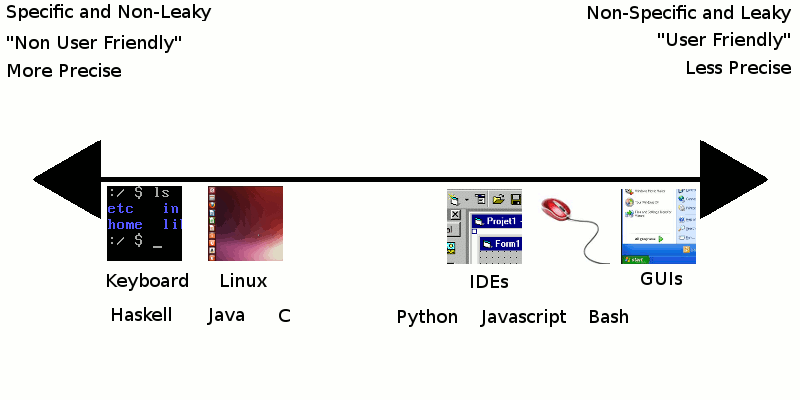
There are probably reasonable arguments to move any of the items in the spectrum above either more to the right, or the left, but you get the idea. Note that you could probably split this up into two spectrums: One for how much the interfaces allow for 'leaky' abstractions, and one for how specific the interfaces are, although in general these two concepts seem to be correlated. Another correlation that I would propose based on my experience is that 'errors' that come from tools on the "Non User Friendly" end of this spectrum are less frequent, and when they do happen, they are more likely to be caused by failures in validation. For the "User Friendly" end of the spectrum, errors are more frequent, and more likely to be verification errors.
The Asymptotic Complexity of Technical Debt
I'm going to start this section with a claim:
The majority of technical debt in a project originates from an inappropriate reliance on abstraction leaks, or a reliance on extremely non-specific interface contracts that have difficult to foresee consequences.
When a project starts there are only one or two modules, and the amount of work you need to do to specify a good interface contract is O(1). If you design a bad interface, the amount of technical debt you will create is O(1) too, so there is not much payoff to taking the time to get the interface contract right. But as the number of modules increases linearly, the worst-case number of inter-module communications increases according to O(N^2). Therefore, if you make bad interface contracts, the worse case number of invocations to these bad interface contracts will scale according to N^2 (if every module talks to every other module.).
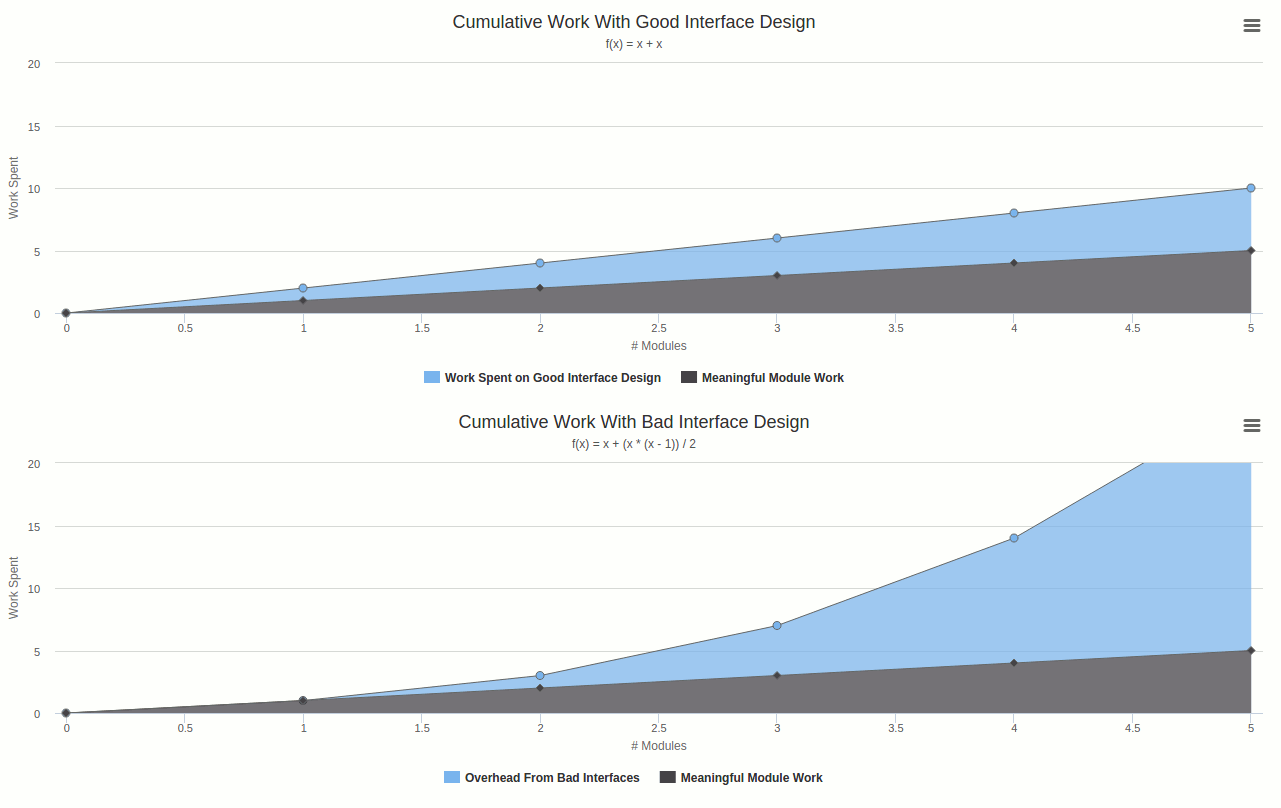
In the above graph, you can see that it is initially less work to avoid creating well-defined interfaces, however, this advantage is quickly overtaken because of the fact that inter-module communication problems will occur at a rate that is polynomial in the number of modules, whereas the work required to create good interface specifications is linear in the number of modules. The polynomial cost comes from considering the handshake problem where in a worst case, every module communicates with every other module. Obviously, the average project will have communication requirements that scale at a rate of less than O(n^2), but it will definitely be more than O(n). There is also another factor that deceivingly shifts the rapid increase off into the future: The human memory. When you first start out, even if you have 20 modules, you can probably keep in your head what all of them do, so vague function names and esoteric conventions are all the contracts that you need. Once the project gets large enough that you forget these, or you bring in someone else, the polynomial cost always dominates.
Why do People Still Use the Command Line?
When you ask this question, people generally give a few different answers, none of which are what I consider to be the most important:
- It is very powerful and flexible.
- The command line uses less resources.
- Using the command line gives you more understanding about how things work under the hood.
The most important reason why we still use the command line is AUTOMATION! It is difficult to overestimate the productivity gain you get by automating tasks. If I need to launch a cluster of 100 servers, are you going to log into each server and manually install your software stack by clicking on a bunch of GUIs? Even if you want to automate the task of clicking on the GUIs, you'd need some kind of file storage that remembers how and where to click on things. Some sort of file full of flexible... commands.
Another general relationship I'll make with the section on quantifying and comparing interfaces, is that even though we could automate things through automated clicks and screen grabbers, this type of communication is designed for humans, and thus it exposes a very non-specific interface that does not allow you to be very precise. The result is that your automatic clicker is very likely to get stuck on a screen because a window moved when it didn't expect it to, or perhaps a colour or font changed. There are too many variables with a GUI. With the command line, everything is much more precise, and you communicate everything through a very narrow unforgiving interface, which is why many humans don't like it but other computer programs do.
There are of course, situations where the imprecise communication of a GUI is a virtue. For example, when doing graphic art work you generally don't care about specifying every individual pixel shade and colour, but you do want something to be specified for every pixel. In this situation the noise from any motions of your hand as you move the cursor actually become meaningful informational content for the final product.
Choosing the Right Language
If you read the section on the asymptotic complexity of technical debt you might come away with the impression that you should always start a project in a language with very specific interface contracts, like Haskell or Java. That is not at all the message I want to convey. If you're making a decision about what language to use for a particular project, I think this question is likely to help:
How likely is it that the requirements for the project will change?
If you're starting a business, the answer is almost certainly going to be 'very likely', especially if you're building a small product from scratch and you're still establishing product market fit. If you already know exactly what the requirements are, for example, if you're building a compiler, or something based on an international standard, then you'd probably answer 'not very likely'.
If you answered 'very likely' to this question, then you would probably want to go with a language that doesn't cause you to waste a lot of time specifying interface contracts, because they will likely work against you when the requirements change. After all, the goal at this stage isn't to get the perfect implementation of the requirements, it is to get the perfect requirements so you can start the final implementation. An exception to this would be if your MVP actually consists of a huge system that is likely to have hundreds of modules. If there are already many people involved in building the software then good interface contracts will be necessary to prevent them from stepping on each others toes.
If you answered 'not very likely' to this question, then you should probably start off with a language that has very strong interface contracts. It will be more work to get started, but it will also be less work to add new features on day number 1523. The only exception, would be if you're writing something small (say a few hundred lines).
Back in the day there was much discussion about how Twitter started out using Ruby on Rails, and then later encountered a number of scaling issues because of this. They later switched to using Scala. Some would probably claim that this represented a failure, and that the right decision was to pick Scala all along. I don't believe this is true. The idea of Twitter itself is extremely simple, so with a number of potential competitors their initial primary goal was to gain enough market share to be dominant. They needed to grow as fast as possible at all costs. This meant iterating on features as fast as possible to figure out what product people actually want them to build. The scaling issues are not a symptom of failure, but a symptom of success. The vision for what the 'product' of Twitter actually was articulated, all that was left was to build it. From the perspective of developers, this is a nirvana like situation that every programmer dreams about, but never experiences: When your boss says "Re-write this crappy code from scratch in your favourite language in whatever way you want so that it is easier to work on later." Re-writing something from scratch when you have a weaker reference implementation is not as much work as figuring out what product you actually need build to start a rocket ship company. Unfortunately, most companies only see this type of switch as an unnecessary cost meant to scratch a programmer's obsessive itch, and waste a lot of time trying to scale something that just wasn't meant to scale.
Why is Python So Popular?
In the section on leaky and specific interfaces, I discussed how you can classify interfaces according to how prone they are to abstraction leaks, and how specific the interface definitions can be. I also pointed out the fact that languages that are considered more 'user friendly' and 'productive' are often the ones that on the highly leaky, and non-specific end of this spectrum.
I claim that the reason Python is so popular is because it is an excellent introductory language due to its extremely lean interface contracts. This is also the same reason that Python becomes difficult to maintain as the size of a project increases.
Python is also very popular in the scientific community, and for people experimenting with numerical computation. The very nature of experimentation requires that you constantly iterate on the design of what you're building, and for this reason more specific interfaces would slow down the experimentation process.
Why is Enterprise Software Usually Java/C++?
I claim that the reason is exactly the opposite reason as in the previous section on 'Why Python is So Popular?'. In the section on leaky and specific interfaces, I discussed the tradeoffs related to different types of interfaces. Interfaces in Java and C++ fall more on the specific end of the spectrum than those found in other languages like Python or Ruby. C++ and Java still can be leaky, and of course there are even more specific languages like Haskell, but Java and C++ seem to strike a balance between scalabilty, user friendliness, and iteration time. These languages also provide the programmer with flexibility in how leaky they would like their interfaces to be as a matter of project convention. An example would be how you can make variables or functions private, public, or protected, depending depending on the needs of the project.
How to Cut Corners Efficiently
If there is one thing you should take away from this article, it is this: If you have to cut corners in your project, do it inside the implementation, and wrap a very good interface around it. You might be thinking that if the implementation is bad enough, then the problems in that implementation can leak to other parts of your system, but they shouldn't! If they do, I would call that bad interface design! For the sake of clarity, I'll explicitly list out what I mean my 'interfaces' here:
- Function Protoypes
- Java 'Interfaces'
- Public Class Methods
- Public Member Variables
- Header (.h) files in C/C++.
- RESTful API endpoints
- URL Routing
- Publicly visible aspects of 'Modules' or 'Packages'
- Database Schema (DDL)
- Many Others...
Conclusion
As you can see, the concept of an 'interface' is an incredibly important one with a variety of far reaching consequences. There are legal consequences, productivity consequences, and a number of very philosophical connections you can make to other aspects of system design. Ask any experienced programmer what they think about interfaces and you're likely to get an earful.
A final thanks to James Hudon who provided some feedback and corrections to this article.
 The Regular Expression Visualizer, Simulator & Cross-Compiler Tool
Published 2020-07-09 |
 Buy Now -> |
 Why Is It so Hard to Detect Keyup Event on Linux?
Published 2019-01-10 |
 Myers Diff Algorithm - Code & Interactive Visualization
Published 2017-06-07 |
 Regular Expression Character Escaping
Published 2020-11-20 |
 How Do Regular Expression Quantifier Work?
Published 2020-08-18 |
 Overlap Add, Overlap Save Visual Explanation
Published 2018-02-10 |
 Silently Corrupting an Eclipse Workspace: The Ultimate Prank
Published 2017-03-23 |
| Join My Mailing List Privacy Policy |
Why Bother Subscribing?
|