How Do Regular Expression Quantifier Work?
2020-08-18 - By Robert Elder
This article is part of a Series On Regular Expressions.
Introduction
In this article, we will discuss regular expression quantifiers with the ultimate goal of developing a very deep understanding of how they work. In fact, by the end of this article you'll understand quantifiers so well, that you'll be able to extend your knowledge to invent a completely new quantifier has never been seen before in any regular expression engine.
By the end of this article, you will understand everything in the following diagram:
| Quantifier Symbol | Min # Matches | Max # Matches | As Many/Few As Possible | Allow Backtracking? |
| ? | 0 | 1 | Many | Yes |
| * | 0 | Infinity | Many | Yes |
| + | 1 | Infinity | Many | Yes |
| {N} | N | N | Many | Yes |
| {,N} | 0 | N | Many | Yes |
| {N,} | N | Infinity | Many | Yes |
| {N,M} | N | M | Many | Yes |
| ?? | 0 | 1 | Few | Yes |
| *? | 0 | Infinity | Few | Yes |
| +? | 1 | Infinity | Few | Yes |
| {N}? | N | N | Few | Yes |
| {,N}? | 0 | N | Few | Yes |
| {N,}? | N | Infinity | Few | Yes |
| {N,M}? | N | M | Few | Yes |
| ?+ | 0 | 1 | Many | No |
| *+ | 0 | Infinity | Many | No |
| ++ | 1 | Infinity | Many | No |
| {N}+ | N | N | Many | No |
| {,N}+ | 0 | N | Many | No |
| {N,}+ | N | Infinity | Many | No |
| {N,M}+ | N | M | Many | No |
| ?💩 | 0 | 1 | Few | No |
| *💩 | 0 | Infinity | Few | No |
| +💩 | 1 | Infinity | Few | No |
| {N}💩 | N | N | Few | No |
| {,N}💩 | 0 | N | Few | No |
| {N,}💩 | N | Infinity | Few | No |
| {N,M}💩 | N | M | Few | No |
Quantifiers are used to quantify how many times a part of your regular expression should be repeated. Every time you want to repeat something in a regex (an individual character, a character class or a sub-expression) you can write a quantifier after it to specify how many times it should be repeated.
The following list shows some examples of the most common quantifiers:
- ?
- *
- +
- {N}
- {,N}
- {N,}
- {N,M}
This article will only discuss these quantifiers within the context of Perl-like regular expressions (not POSIX regular expressions). This is worth mentioning since the older POSIX style regular expression quantifiers lack certain features, and have significantly different behaviour in some cases.
Most typical guides to regular expressions would probably start by immediately diving into a detailed description of what each of these symbols does. They would probably start by explaining the meaning of the '*', '+', and '?' symbols. However, this won't be your typical guide to regular expressions.
Range Quantifiers
Instead, we'll start by focusing on understanding this quantifier:
{N,M}
The reason for this atypical approach is simple: Once you understand what this quantifier does, you're already 50% done learning everything there is to know about quantifiers. Let's do a few examples.
Assume you need to write a regular expression that can match both spellings of the word 'enroll'. The word 'enroll' can sometimes be spelled with one 'l' or two 'l's depending on whether the author chooses to use British or American spelling conventions. Using this regex:
enrol{1,2}
you'll be able to match both spellings of 'enroll':
- enrol
- enroll
Here is a link to an interactive visualization of the regex enrol{1,2}
In this case the quantifier is the '{1,2}' part. The '{1,2}' quantifier can be interpreted in English to mean "Whatever came just before this quantifier, repeated anywhere from 1 to 2 times.". If you wanted to change the regex to also match any misspellings of 'enroll' that have 3 'l's, you could just change the upper bound of the range from 2 to 3:
enrol{1,3}
And now, using the regex above, you can match all three spellings of the word 'enroll':
- enrol
- enroll
- enrolll
You could go even further and change the regex to include misspellings that don't have any 'l's at all, by decreasing the lower bound of the range 0:
enrol{0,3}
Using the regex above, you can match these four (miss)spellings of the word 'enroll':
- enro
- enrol
- enroll
- enrolll
The pattern that this quantifier uses should now be a bit more obvious: Whenever we want specify that the previous character can be repeated a lower bound of N times up to an upper bound of M times, we can write this quantifier after the character:
{N,M}
Of course, the letters 'N' and 'M' here are placeholders that are used for the purposes of documentation. In reality, you would never literally write '{N,M}' as a quantifier in your regular expression. You would would write something like '{2,8}', '{0,20}' or any other pair of positive integers.
Range Quantifier Defaults
In order to make things crystal clear, there are a few cases where the endpoints of the range are not explicitly written, but are instead implied. Here is an example:
a{,5}
The interpretation of this quantifier is to repeat the character 'a' anywhere from (it doesn't matter times) to 5 times. Another way to describe the same thing would be to say "repeat the character 'a' anywhere from 0 times to 5 times" which you could do with the following equivalent regex:
a{0,5}
You'll sometimes see the same thing with the upper bound of the range:
a{3,}
and in these cases the upper end of the range is assumed to be "Infinity", however there is no equivalent way to write this explicitly. You simply can't write something like this:
a{3,Infinity} (This does not work)
since most regex engines will default to interpreting the range quantifier as literal text if it doesn't see the format it expects. Therefore, when the upper bound of your range is 'infinity', you must simply omit the second number like this: '{3,}'.
One final important case to consider is when a single number is used to describe that the previous character should be matched exactly the number of times specified. For example, this regex will match any sequence of exactly 4 'a' characters:
a{4}
If we wanted to re-write this using a range, we could write:
a{4,4}
which means the same thing.
Every Quantifier As A Range
Of the quantifiers we've reviewed so far, it should be clear that they can all be re-written in the following standardized form:
{N,M}
where
- 'N' is a positive integer.
- 'M' is a positive integer OR left blank to represent 'infinity'.
What About The Quantifiers '?', '*' and '+'?
We still haven't discussed the meaning of the '?', '*' and '+' quantifiers, so let's do that now:
- '?' is just syntax sugar for '{0,1}'.
- '*' is just syntax sugar for '{0,}'.
- '+' is just syntax sugar for '{1,}'.
Here is an example interactive visualization showing the '?' quantifier that makes the character 'a' optional. As you can see, the control flow graph splits into two possible paths: One that skips the character 'a', and one that requires it. If one path fails, the regular expression engine simply backtracks to try the other path.
Here is an example interactive visualization showing the '+' quantifier that matches the character 'a' one or more times. As you can see, the control flow graph starts by requiring an 'a' character. If there are no 'a' characters, it fails immediately. If there is at least one, control will split into two possible paths: One path goes back to try and get yet another 'a' character, and the other continues with the rest of the regex. By default, the regex engine will first try the path that consumes yet another 'a' character until there are no more in the search text.
Here is an example interactive visualization showing the '*' quantifier that matches the character 'a' zero or more times. As you can see, the control flow graph starts by splitting into two possible paths: One path immediately continues on with the rest of the regex, and the other attempts to consume an 'a' character. By default, this quantifier will first try the path that consumes an 'a' character. Once it fails to find another 'a' character, it will give up and continue on with the rest of the regex.
A Brief Summary
Here is a table to summarize what we've learned so far:
| Quantifier Symbol | Normalized As A Range | What It Really Means |
| ? | {0,1} | "Repeated from 0 to 1 times." |
| * | {0,} | "Repeated from 0 to Infinity times." |
| + | {1,} | "Repeated from 1 to Infinity times." |
| {N} | {N,N} | "Repeated from N to N times." |
| {,N} | {0,N} | "Repeated from 0 to N times." |
| {N,} | {N,} | "Repeated from N to Infinity times." |
| {N,M} | {N,M} | "Repeated from N to M times." |
Quantify Individual Characters, Character Classes, or Sub-expressions
As discussed previously, quantifiers can be used to specify how many times a character in your regular expression can be repeated:
a{0,5}
But, you can also apply quantifiers to character classes too:
[0-9]{0,5}
For example, you could use this regular expression to match chapter titles in a book, regardless of how many digits are in the chapter number:
[Cc]hapter [0-9]+
And most importantly, you can also apply a quantifier to a sub-expression to repeat a sequence of characters. For example this regex:
(Hello){2,5}
will match any of the following strings:
- HelloHello
- HelloHelloHello
- HelloHelloHelloHello
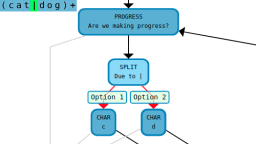
You can even apply quantifiers to a sub-expression that contains an alternation. This regex:
(cat|dog|bird){1,2}
will match any of the following strings:
- cat
- dog
- bird
- catcat
- catdog
- catbird
- dogcat
- dogdog
- dogbird
- birdcat
- birddog
- birdbird
You're Half Way There
Just as promised earlier, you're already 50% done learning everything there is to know about quantifiers. There are many more quantifiers than what we've seen so far, but fortunately, there are only 4 fundamental aspects to every regular expression quantifier, and you'll understand them all by the end of this article. Here are those 4 aspects:
- 1) The minimum number of times it can match.
- 2) The maximum number of times it can match.
- 3) Whether it prefers to match as many times as possible, or as few times as possible.
- 4) Whether it will disable backtracking or not.
and as you can see, we've already covered the first two, so 2/4 = 50% done.
Greedy/Lazy - As Many/Few As Possible
Now let's cover item #3 from the list above: "Whether it prefers to match as many times as possible, or as few times as possible.". Consider a case where we want to match this regular expression:
a{2,4}(aabbcc|bb)
against this piece of text:
aaaabbcc
You can follow through the matching process with an interactive visualization of the matching process for this regex here.
Since the quantifier '{2,4}' can match the 'a' anywhere from 2 times to 4 times, and the text we're searching starts with 4 consecutive 'a's, it's ok for the regular expression engine to go ahead and match all 4 of them. After matching the 4 'a's, the quantifier has been satisfied, so we move forward to try and match the '(aabbcc|bb)' part of the regex. We've already consumed the 'aaaa' part of the string, so only 'bbcc' remains. Therefore, the alternation can only make use of the 'bb' which satisfies the overall regular expression and the completed match is 'aaaabb':
aaaabb
But what if we had been less 'greedy' and decided to only accept two 'a' characters at the beginning instead of all 4 of them? After all, that is in the acceptable range that the quantifier '{2,4}' allows. It turns out, that if we did only take 2 'a' characters, the alternation would have been able to match 'aabbcc' instead of just 'bb', and the resulting match would have been two characters longer:
aaaabbcc
The overall conclusion here is that whenever you use a quantifier, there is an implicit question about whether you want the quantifier to prefer to match as many as possible or as few as possible times. It turns out that every quantifier we've discussed so far will always try to be 'greedy' and try to match as many times as possible given the opportunity.
Lazy Quantifiers - Just Add '?'
Once again, here is the list of every quantifier we've seen so far. These quantifiers are all 'greedy' by default, meaning that they will try to match as many times as possible:
- ?
- *
- +
- {N}
- {,N}
- {N,}
- {N,M}
So how do you make them try to match as few times as possible? That's easy, just stick a '?' character after any quantifier:
- ??
- *?
- +?
- {N}?
- {,N}?
- {N,}?
- {N,M}?
These are commonly known as 'lazy' quantifiers. They're also sometimes called 'reluctant'.
As mentioned in the introduction, the older POSIX style regular expressions exhibit a number of differences, and this (along with the rest of this article) is one such case. POSIX style regular expressions do not include support for the concept of 'greedyness' or 'lazyness'.
And that's pretty much all there is to say about 'lazy' quantifiers. Here is an updated version of the animation from the previous section that shows the matching process for 'a{2,4}?(aabbcc|bb)' with the string 'aaaabbcc'.
Quantifiers & Backtracking
There is still one remaining concept to consider when it comes to understanding quantifiers: Backtracking. When you use a quantifier like '{2,5}' it will try to match as many as 5 times, but you still could end up with a match that only repeats 2,3, or 4 times (depending on the text you're searching).
In order to understand why you could end up with a number of repetitions that's in the middle of your range (like 3 or 4 in example just mentioned) you need to understand the decisions that are made during the matching process. In a regex like 'a{2,4}(aabbcc|bb)' the quantifier '{2,4}' specifies that the first 2 'a' characters are mandatory. If the text being searched doesn't have at least two consecutive 'a's (the minimum specified by the quantifier range), the regex will fail to match completely and there's nothing more to consider. If it does have at least two 'a' characters, immediately after it accepts these two 'a's, the regex engine has to start making choices: "Should I stay here and keep trying to match 'a' characters, or should I take what I've got and move on to try and match the '(aabbcc|bb)' part?". This potential 'choice' is considered every single time another optional character is accepted by a quantifier once it has satisfied the minimum number of repetitions that are required by its range. For greedy quantifiers, the default first choice is always to try and get more. For lazy quantifiers, the default first choice is always to take what you've got and try to continue.
For the 'greedy' quantifiers, whenever the regex engine makes of these choices, it will save what was doing at that time so it can possibly 'backtrack' to the same position and possibly try the other option. This will need to happen if it ends up discovering that taking too much causes the entire match to fail. It will then try the rest of the match by taking one less at that position.
For the lazy case it is the opposite: It will remember to 'backtrack' and take one more repetition if taking too little causes the entire match to fail.
Possessive Quantifiers Disable Backtracking
There are occasionally situations where you'd like a quantifier to try and greedily match as many times as possible, but also to never give up any of the characters it has already matched, and instead fail the overall match instead of trying to backtrack. For example, consider the process of trying to match this regex:
a{1,10}aaaaaaaaaaX
against this piece of text:
aaaaaaaaaaaZ
You can follow through the matching algorithm using this animation here. As you can see from the animation, the regex never matches the search string, but it spends a huge amount of time backtracking!
In this case, the '{1,10}' quantifier is 'greedy', so it will go ahead and try to consume as many 'a' characters as it's allowed to before moving on to the next pattern. It just so happens, that the pattern after this quantifier also consists of a long string of 'a's, and there aren't enough 'a' to share between both parts of the pattern! In fact, the regex engine will first try the entire search by choosing 10 'a's, only realizing at the 'Z' character that it made a mistake. Then it tries again with 9, then with 8 and so on until it tries to consume 1, and only then does it realize that the entire pattern won't match and fail.
In this case, a 'possessive' quantifier can be used to speed up the process of failure. It does this by disabling the ability to 'backtrack' and re-attempt the rest of the match with one less repetition. For this use case of possessive quantifiers, we're only concerned with speeding up failing matches rather than matching something different. Here are a few examples to show the contrast between regular greedy and possessive quantifiers in this case:
echo "aaaaaaaaaaaZ" | grep -Po "a{1,10}aaaaaaaaaaX"
gives the following output:
(nothing)
Again with greedy, but changing the Z to X in the input:
echo "aaaaaaaaaaaX" | grep -Po "a{1,10}aaaaaaaaaaX"
gives the following output:
aaaaaaaaaaaX
Now, if we repeat these two tests with possessive quantifiers:
echo "aaaaaaaaaaaZ" | grep -Po "a{1,10}+aaaaaaaaaaX"
gives the following output:
(nothing)
Again with possessive, but changing the X to Z:
echo "aaaaaaaaaaaX" | grep -Po "a{1,10}+aaaaaaaaaaX"
gives the following output:
(nothing)
As we can see above, using a possessive quantifier will still cause the match to fail if it also failed when using a greedy quantifier, but now it will also fail in cases where a greedy quantifier would have consumed 'too much' on its first attempt.
Any quantifier can be made 'possessive' by simply sticking a '+' character on the end of it:
- ?+
- *+
- ++
- {N}+
- {,N}+
- {N,}+
- {N,M}+
I will suggest, rather opinionatedly, that possessive quantifiers aren't particularly useful. Many things that you might want to do with a possessive quantifier can likely be accomplished by another method. It is also true that many modern regular expression engines use optimizations and algorithmic tricks that often (but not always) make manual optimizations like this unnecessary. Still, this guide would not be complete without discussing possessive quantifiers.
The 'Pile Of Poo' Quantifier
From our list of '4 fundamental aspects to quantifiers', item #3 was about preferring to take as few as possible versus as many as possible. Item #4 was about the option to disable backtracking or not. In terms of discussing these two remaining aspects, we have so far considered these three possible combinations:
- As many as possible with backtracking allowed: Nothing after the range.
- As few as possible with backtracking allowed: '?' after the range.
- As many as possible with backtracking not allowed: '+' after the range.
But we're missing one combination: What about 'As few as possible with backtracking not allowed'? Is there a quantifier symbol for that? No there isn't! At least no one has invented it yet, which is exactly what I'm going to do right now, right here in this article. Introducing the 'pile of poo' quantifier:
- ?💩
- *💩
- +💩
- {N}💩
- {,N}💩
- {N,}💩
- {N,M}💩
Similarly to how it's done with the 'lazy' and 'possessive' quantifiers, the 'pile of poo' quantifier is described by taking one of our familiar quantifiers, and putting a 'pile of poo' or '💩' emoji character after it (Unicode: U+1F4A9).
Now let's take a moment to consider the properties of this quantifier. It is a lazy quantifier that always takes as few characters as possible, and it also does not allow backtracking. So a quantifier like a{3,5}💩 would first match 3 repetitions of the letter 'a' and then opt to try and continue matching the rest of the regular expression without trying to match more repetitions. Since this quantifier disables backtracking though, it can never attempt to backtrack if it finds that it needs to accept more 'a' characters to match the overall regular expression. Instead, it just accepts 3 'a's and then continues with the rest of the regex. If the rest of the regex fails, that's it! There will be no match!
Therefore, the quantifier a{3,5}💩 is really just going to do the same thing as a{3}💩 so there is really no reason to invent this quantifier at all (which is probably why no one did), since it doesn't do anything new. The greedy version of this quantifier (the '+' possessive quantifier) does make sense since the number of matched optional repetitions can be different each time.
{N} And {N,N} Are Special Cases
Something that was hinted at in the previous section, but not adequately discussed, is the fact that {N} And {N,N} are special cases. As we discussed previously, any quantifier can be associated with a 'min' and a 'max' number of acceptable repetitions. The quantifier {N}, which can be re-written as {N,N} is an interesting special case when we consider greediness, laziness and backtracking. Most regular expression engines support using the quantifiers '{N}?', '{N,N}?', '{N}+' and '{N,N}+' but in reality, there is no difference between greedy, lazy, or possessive quantifiers when the upper limit and the lower limit of the range are equal! For this range, the first N repetitions are always mandatory and there are no optional repetitions. In this case, the regular expression engine will never have to make decisions or backtrack, so these extra matching preferences don't matter.
The 4 Fundamental Quantifier Types
Here is a summary table that provides an overview of the 4 possible combinations of greedy or lazy and enabled or disabled backtracing:
| People Call This | Put This After The Range/Symbol | As Many/Few As Possible | Backtracking Allowed? |
| Greedy | (nothing) | Many | Yes |
| Lazy/Reluctant | ? | Few | Yes |
| Possessive | + | Many | No |
| Pile Of Poo | 💩 | Few | No |
It should be pointed out that most people would get confused if you called the 'possessive' quantifier 'greedy' since these three different types of quantifiers have taken on the colloquial names of 'greedy', 'lazy', and 'possessive'. However, I do think it makes sense to say, descriptively, that 'possessive' quantifiers are 'greedy' in the sense that they take the locally available best solution at every step, which is really what the definition of a 'greedy' algorithm is. Therefore, I believe that the column for 'As Many/Few As Possible' should really be called 'Greedy/Lazy' instead, but I did not name it this way to avoid creating any confusion.
This article is part of a Series On Regular Expressions.
 The Regular Expression Visualizer, Simulator & Cross-Compiler Tool
Published 2020-07-09 |
 Buy Now -> |
 Regular Expression Character Escaping
Published 2020-11-20 |
 Interesting Regular Expression Test Cases
Published 2020-07-09 |
 How Regular Expression Alternation Works
Published 2020-08-18 |
 Character Ranges & Class Negation in Regular Expressions
Published 2020-05-31 |
 Guide To Regular Expressions
Published 2020-07-09 |
 Character Classes in Regular Expressions - A Gentle Introduction
Published 2020-05-10 |
| Join My Mailing List Privacy Policy |
Why Bother Subscribing?
|