An Overview Of Computer Science Concepts For Engineers
2017-03-05 - By Robert Elder
Who Should Read This?
This article is targeted at engineering majors from disciplines other than software engineering (such as electrical or mechanical) who are interested in learning more about what topics exist in the field of computer science and software engineering. You may also benefit from this article if you graduated from a computer science program more than 10 years ago, since this field is rapidly changing and there may be new concepts that you haven't heard of before.
Various theoretical topics will be mentioned, but particular emphasis will be placed on those topics which are especially relevant in today's job market. This article is optimized for people who are already very technical, mathematical and fast learning. This article is not intended to teach you any of these topics, but instead to let you know that they exist and explain why they are important so you can go learn them on your own.
Computer Science Theory
- A Turing Machine is an important theoretical model of computation that is used by computer scientists to make claims and proofs about how powerful certain languages and computational systems are. It is related to the concept of Turing completeness.
- The Von Neumann architecture is an important model for implementing actual physical computers that also provides the benefits described by the more theoretical Turing machine. Previous to the Von Neumann architecture, computers were physically hard-wired to perform calculations is a specific sequence, but with the Von Neumann architecture, they could be re-programmed by changing the data in their memory instead of physically re-wiring them.
- Real computational machines are usually classified as either register machines or stack machines.
- Big O notation is a notation used to describe the eventual dominating growth rates of functions. It is used heavily in the study of asymptotic complexity as a method of comparing which algorithm will make a more favourable use of resources (usually memory or CPU).
- NP-completeness is a term used to describe a collection of problems for which there is currently no known way to solve quickly. Specifically, the only way we know how to solve them requires a run time that go up exponentially as the problem size increases and can potentially take astronomical amounts of time to finish (thousands of years). Most every-day problems have known solutions which run in polynomial and are much faster. Furthermore, all problems in this group can be quickly converted into each other, so solving one of them quickly would allow you solve all of them quickly.
- The P versus NP problem is an open problem in mathematics and computer science for which there is a $1,000,000 available for the first correct proof. In relation to the previous point about NP completeness, the N = NP problem asks the question: "Does there exist any polynomial time algorithm for any NP-complete problem?". If a polynomial time algorithm was discovered, it would have massive practical consequences for many areas of computer science.
- The Halting Problem is an important theoretical problem in computer science that states that it is not possible to write a computer program that can analyse another computer program to tell if it will eventually stop running or not. It is possible to write a program that can do this for other specific simple programs, but it is not possible to write a program that correctly determines if any program will halt.
- Transactions represent work that must be done either completely or not at all. The concept of transactions appears most often in databases, but it still applies to a number of other places in computer science. The fundamental idea is that in a transaction you need to take extra care so that it is impossible to leave things in an intermediate state in the event of something like a power failure.
- Finite-state Machines appear throughout computer science.
- DFAs and NFAs are finite state-machines which are commonly used to model string parsing. They are often used to model regular expressions.
- Recursion is when a function calls itself. The concept of recursion itself isn't all that complicated, but it is a frequent source of confusion for people who haven't worked with it a lot before. One reason for the confusion is that people often have difficulty visualizing stack frames.
Compilers
- Context-free Grammars are a fundamental tool used for describing what sequences of text can be used to construct a valid computer program. In practice, you can create a 'grammar' for a new programming language then use this grammar to write a program that can execute (or do other things with) code from your newly invented programming language.
- Extended Backus-Naur form is a commonly used representation for describing context-free grammars.
- An LR Parser is a common type of parser that constructs a parse tree by starting at the bottom of the tree and moving up.
- An LL Parser is a common type of parser that constructs a parse tree by starting at the top of the tree and moving down.
- Lexing is often one of the first stages of compiling a computer program where parts of the program text are chunked together in a meaningful way.
- Parsing is the phase of a compiling a computer program where some form of parse tree is created to represent the entire program. Once this is done the syntax tree is handed off to later stages of the compiler.
- A Deterministic Finite Automaton is a model that is closely related to state machines. It is often used to describe what sequence of characters can appear in a given context (such as in a compiler's lexer).
- Optimization is a vast topic in the field of compiler development that would take you a thousand lifetimes to explore everything there is to consider.
- Linking is one of the steps involved in making a fully executable program where smaller chunks of compiled code are connected together in order to include all the pieces necessary for a fully functional final program. It is particularly important in large applications that can have hundreds of components written by different people.
- An Interpreter is a piece of software that is used to run programs without completely compiling them down to machine instructions for the host's target CPU first. Interpreters can use varying degrees of emulation to achieve this, and they are often used with languages that are specifically intended to be 'interpreted'. Many languages that are usually interpreted can also be compiled down to byte code in order to make they run faster.
- GCC is one of the most popular C/C++ compilers for Unix based operating systems.
- Clang is a newer compiler that is a major competitor to GCC with various pros and cons.
- 'LLVM' refers to a number of things, and is most often associated with the Clang compiler collection and related tools.
Operating Systems
- The Kernel is the core part of an operating system that interacts directly with the hardware. Its purpose it to provide higher-level tools to the rest of the operating system and user programs. For example a kernel will often allow you to launch new processes and threads, request heap memory for a process, or allow a process to be blocked.
- A Shell is the layer that goes over top of the operating system kernel (think of a nut with a shell around the kernel). The shell provides a user-friends interface that allows the user to easily tell the kernel to do various things like launch processes, kill processes, write to disk, etc.
- 'The Stack' is a region of memory assigned to each thread of execution of a process that runs in an operating system. It is a very fundamental concept that is found in virtually every operating system and a stack can even be used in small embedded programs that don't run inside the context of an operating system. A program's stack stores temporary information and keeps track of what location to return to after a function call has completed (as well as other things).
- 'The Heap' is a region of memory that the operating system sets aside to give to programs when they require large contiguous memory regions of a given length. The heap is different than the stack because the programmer must explicitly request for heap space to be allocated and freed, but this is not true of the stack.
- The Scheduler is the part of the operating system that decides which program should run next. A modern OS can have hundreds of programs running but only a few CPU cores to run them on. The scheduler is responsible for efficiently solving the problem of choosing which thread to run next and where it should run. The scheduler is part of the operating system kernel.
- Context switching is one of the fundamental methods that an operating system running on a single CPU can use in order to run multiple programs one after another. This can be done quickly enough to make it look like many programs are running at the same time from a user's perspective.
- Virtual Memory is a level of indirection that allows the operating system to control what region of physical RAM actually gets accessed when a program access a particular memory 'address'. Historically, programs would simply control physical address of byes in RAM, but this was not flexible or portable so virtual memory was invented.
- A window manager is a common graphical software component that manages the layout of windows and controls how windows interact with other graphical elements on the screen.
Software Testing and Verification
- Unit testing is a practice where software components are tested as individual 'units'. Unit tests are often extremely quantitative are are likely to be run as automated tests.
- Integration testing is the practice of bringing together individual software components and testing them after they have been 'integrated' together. This catches bugs that wouldn't otherwise be expected, such as components that attempt to communicate with each other using the incorrect protocols, or unexpected environmental differences.
- Test Driven Development is a style of software development that proposes that you should write tests for a feature before you write the feature itself.
- Real-time Programming considers programming environments where the software must respond to real-world time-based constraints. These real-time events could be simulated, for example in an animated movie rendering, or in the case of soft or hard real-time systems that respond to real-time events in the physical world. Examples of hard real-time systems would be autopilots that control aircraft systems, or a pacemaker. Hard real-time software is typically required to follow rigorous coding standards such as MISRA C due to their high cost of failure.
- A Control Flow Graph is a representation of a computer program that shows all possible paths of execution in the form of a directed graph. It is commonly used for static analysis, optimization, and in the creation of test cases.
- Cyclomatic Complexity is a measure of how complicated a program's control flow graph is.
- Static Analysis is the process of analysing code and looking for possible design problems before the program has been run. The advantage here is that if you can find bugs with a given static analysis technique, you don't need to wait for the bug to occur in order to find it.
- Dynamic Analysis is the process of analysing a running program to find error states. This is often less desirable that finding the bugs using static analysis, but dynamic analysis can often find bugs that static analysis can't. Dynamic analysis can also miss bugs if your program never gets sent the right inputs to make the bug appear.
- Input Space Partitioning is a technique used in software testing to assign 'partitions' to the large input space of possible test cases for a given piece of software. Based on the programmer's judgement, the partitions can be created so that there is at least one important test case in each partition. This way, you can choose one test case from each partition instead of randomly choosing mostly repetitive test cases.
- Software validation is the process of ensuring that a piece of software does what the customer wants it to.
- Software verification is the process of ensuring that software meets its specification (regardless of whether that specification produces the product that the customer actually wants or not).
Software Engineering Interviews
- Big O Notation (mentioned previously).
- Algorithms and data structures are frequent topics of interview questions.
- Design Patterns also come up frequently in interviews.
- Interviewers will commonly ask you to write code on a whiteboard.
- Fizz Buzz is a commonly asked programming filter question. It is intended to be a very easy to pass programming test, so make sure you've read about it before.
- Read Stories & Tips: 50+ Interviews With Facebook, Twitter, Amazon & Others for more information.
Software Development
- JSON is an extremely popular format used to store data outside of computer programs. It is often used when communicating data through a web-based request, but it is found in many other places.
- XML is another popular method of storing data outside a computer program. It can be compared and contrasted with JSON.
- Git is an extremely popular version control tool. It is used to keep backups of your source code, but also allows you to share and collaborate with teams of other software developers. If you plan to write software for a living you should definitely learn Git because most companies use it already or are moving toward it. Less popular alternatives to git are SVN, Perforce, or Team Foundation Server (and many others).
- Floating Point Rounding Errors are an extremely common source of confusion among people who are not familiar with them. Floating point numbers are also a common source of confusion for people who are very familiar with them.
- Integer Division Rounding Errors are possibly surprising at first, but you'll get used to them.
- Code Review is often done by companies to make sure their production code remains high-quality.
- Pair Programming is a technique where two people will sit at one workstation with one person directing what should be done, and the other person doing it. It is an effective way to mentor new programmers and spread knowledge about how to do tasks quickly.
Important Algorithms And Problems
- Knapsack Problem
- Travelling Salesman Problem
- Dijkstra's Algorithm
- Dynamic Programming
- Merge Sort
- Quicksort
- Insertion Sort
- Lamport Timestamps
- Binary Search Tree, search, insert, and delete
- Linked List, search, insert, and delete
- Circular Buffer add and remove
Multi-processing And Synchronization
- The Producer Consumer Problem is a commonly encountered problem where multiple threads of execution want to add or remove from a shared buffer. This problem sounds simple, but it is actually extremely difficult and there are many variations on how to solve it under various different constraints.
- A Semaphore is a tool used to solve various multi-programming problems.
- A Mutex is another tool used to solve various multi-programming problems.
- Semaphores and mutexes can be used to implement locks.
- Amdahl's law is a formula that can be used to calculate the theoretical benefit from speeding up part of a task to take advantage of parallel processing.
- Deadlocks are a common problem in a multi-programming environments.
- Distributed Systems present a number of multi-programming challenges that can occur across large networks of computers.
- Atomicity is an extremely important requirement for certain operations that must occur in a multi-programming environment.
Important Data Structures
- A Stack is a data structure that you could visualize as a stack of dishes: You can either put a new dish on top of the pile, or take one off of the top, but you can't remove or insert anything directly in the middle.
- A Queue is a data structure that works just like a standard line people wait in at the grocery store: People are served in the order in which they arrive. It's no surprise that the British word for 'line up' is queue.
- A List is guaranteed to remember ordering of elements, and also allows for duplicate elements.
- A Set does not preserve ordering of elements, and does not allow for duplicate elements.
- A Dequeue is similar to a queue, but elements can be added or removed from either end.
- A Binary Search Tree is a tree based data structure where each item has a maximum of 2 children, and each child satisfies some property with respect to its parent.
- A Heap is a tree based data structure where a given property is satisfied between every node and its children.
- A Linked List is a method of implementing a list where each node in the list maintains a reference to the next node in the list.
- A Directed Graph is a set of points (vertices) and lines (edges) connecting those points where each edge also has a direction associated with it.
- An Undirected Graph just like a directed graph where there is no direction information associated with each edge.
- A Map is a set of key and value pairs where each key can be used to look up its associated value.
- A Hash Table is a data structure that used a hash function to take a variable length key, and map it to a fixed length number which can be used to locate or store something in a hash bucket. A hash table can be used to implement a map. Finally, hash tables are often the 'correct answer' to many job interview questions.
Software Design
- UML is a standard for visually representing software components.
- Software Design Pattern: common solutions to common problems.
- Interfaces are an extremely important (but abstract) topic in software engineering. They allow us to formalize guarantees about what software will do, while ignoring irrelevant implementation details.
- The concept of an Implementation is contrasted from that of an interface: You should never rely on an implementation detail because it is considered to be part of the unpredictable working of the inside of a black box that will probably change in the future.
- Defensive Programming involves being cautious of unforeseen errors or confusion when writing programs.
- Object Oriented Programming is an extremely popular programming paradigm where data and functions are packaged together inside 'objects'.
- Inheritance is a feature offered by many programming languages that allows classes to 'inherit' some aspects of other classes.
- The Law of Demeter is a programming principle that encourages you to write code that maintains a clear separation of concerns.
- Information Hiding is a programming principle that encourages hiding of implementation details where they cannot be accidentally exposed and depended upon by other parts of the software.
Web Software Development
- A RESTful API is a commonly encountered method of implementing a web-based interface that accepts interactions from other computer programs.
- DNS is the system that translates names like 'google.com' into an IP address which lower levels of the network stack can talk to.
- If you become a web developer, Inspect Element will be one of your primary debugging tools.
- SQL Injection is a common vulnerability (not limited to web applications) where the user is able to modify database queries in a way that the programmer did not expect.
- Javascript is the primary client-side programming language for web applications.
- XSS (Cross Site Scripting) is a type of web vulnerability where an attacker is able to inject Javascript onto a page and have this script run for other users.
- If you pursue a career in web development, be mindful of the fact that there are Many Javascript Libraries and it is not uncommon for them to have backward-incompatible newer versions released or simply get abandoned. Be careful about what you wasting your time learning.
- Minification is commonly performed on Javascript or CSS files to reduce their file size. This makes web pages load faster while their functionality remains the same.
- A Web Server is a piece of software that responds to HTTP requests. Whenever you browse to any web page, it is a web server that sends back the web page to you.
- A Database Server is a piece of software that is responsible for storing and retrieving data quick and efficiently. Databases often store data that isn't efficiently stored in regular files because of requirements to change the data often, or searching it faster than can be done in a regular file system.
Database Software
- SQL is a standardized language for reading and writing from a database. It is based on Relational Calculus and Relational Algebra.
- The Entity-relationship Model is a method of representing relationships between things in a database.
- NoSQL Databases are an alternative to SQL databases. By avoiding many of the formalities that come with SQL databases, NoSQL databases can offer some performance advantages. In some cases this is done at the cost of data integrity.
- Isolation Levels describes the degree to which database queries can affect other queries that may be running concurrently.
- Transactions are concerned with applying a collection of database queries either completely or not at all. The outcome of a transaction will either be to commit or rollback.
- ACID: (Atomicity, Consistency, Isolation, Durability) a set of important properties of database transactions.
- Boyce–Codd normal form is one of several normal forms that are intended to reduce the amount of data duplication in a database. Reducing data duplication saves disk space, and also reduces some common sources of mistakes.
Networking
- The Internet protocol suite is a collection of internet communication protocols that you could spend a lifetime learning.
- A ping test is a common test to measure the latency between two computers, or to identify if the remote computer is even able to respond.
- The world is currently in the middle of a long-term migration away from the older IPV4 internet protocol to the newer IPV6 protocol.
- DHCP is the protocol that (among other things) assigns your computer an IP when you connect to your home router.
- HTTP is the protocol that web servers respond to as you browse to web pages. HTTPS is the secure version of this protocol that encrypts information sent between you and the web server.
- SSH is a secure method you can use to connect to a remote machine over the internet. You can use SSH tunneling to do various things like control a remote machine or set up and interact with remote services through a secure channel.
- The 192.168.X.X IPV4 address space is reserved for private networks. It is likely that your home router and home devices are given 192.168.X.X based addresses, so you will see '192.168' frequently.
- localhost is a frequently used hostname that has been standardized to mean 'the current computer'. It is usually mapped to the IPV4 address 127.0.0.1. It is extremely useful for testing services locally before testing them over a network in order to isolate the source of problems.
Security
- Symmetric-key Cryptography is the intuitive method of secure communication where you use the same secret key to encrypt messages and to decrypt them.
- Public-key Cryptography is a secure communication scheme that involves two keys: A private key, and a public key. The public key is distributed 'publicly' can be used to encrypt messages, but not decrypt them, and the private key is kept 'private' and can encrypt or decrypt messages.
- A Side-channel Attack is an attack on a cryptographic system that takes advantage of an unexpected 'side channel' of information leakage. For example, you could analyse the sound of a computer processor to attempt to re-construct its internal state when encrypting some information.
- A Buffer Overflow is an extremely common type of security vulnerability where a programmer accidentally writes code that can read past the end of a buffer. This can almost always be exploited by users who have internal knowledge of the program stack and memory layout to cause the program to execute arbitrary code of their choosing.
- A Port Scanner is a tool you can use to scan a host to check if there are services running on any open ports. This can be done for legitimate reasons, but it can also be done by potentially malicious users looking for security vulnerabilities.
- A brute force attack is an attempt to compromise a cryptographic system by simply trying every possible solution. This type of attack works when someone uses weak passwords or poorly implemented cryptography, but in a well-designed cryptosystem it is usually impractical.
 The Regular Expression Visualizer, Simulator & Cross-Compiler Tool
Published 2020-07-09 |
 Buy Now -> |
 Why Is It so Hard to Detect Keyup Event on Linux?
Published 2019-01-10 |
 Myers Diff Algorithm - Code & Interactive Visualization
Published 2017-06-07 |
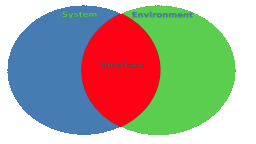 Interfaces - The Most Important Software Engineering Concept
Published 2016-02-01 |
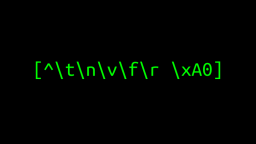 Regular Expression Character Escaping
Published 2020-11-20 |
 How Do Regular Expression Quantifier Work?
Published 2020-08-18 |
 Overlap Add, Overlap Save Visual Explanation
Published 2018-02-10 |
| Join My Mailing List Privacy Policy |
Why Bother Subscribing?
|